
Training machine learning models with Airflow and BigQuery
WePay uses various machine-learning models to detect fraudulent payments and manage risk for payers, merchants and their platforms.
The Problem
In a previous blog post, our Data Science team described how we use a Random Forest algorithm to achieve an optimal combination of model and system performance in building an automated machine learning pipeline that refreshes daily. We are able to use the refreshed models to fight fraudsters who commit collusion fraud, perform credit card testing using stolen cards, or take over accounts.
As our data grows, we need to retrain the models faster while consuming fewer resources. We also want to refresh the models more frequently, so as to make use of newly detected fraud patterns to fight more complex attacks.
The Historical Approach
WePay started off by using a single server node to handle the entire workflow as described in the figure 1:
- Signals pull from BigQuery - Run a few long BigQuery queries to pull multi-day transactional information from various tables, so that we have all the existing data stored on a flat file local to the single server node.
- Rollup and Merge - Transpose the key-value pair of transaction signal data into a multi-column, sparsely-populated data table. Each row of the table represents an event/payment which has all the needed features for further processing of the event. This is still all on flat files.
- Tagging Fraud and down-sampling - WePay specific rules for tagging certain payments as fraudulent and targeting a mixture of fraud and non-fraud payments as the source of training data.
- Variable creation - The first step for preparing feature data as input for the model training.
- Imputation and aggregation - Interpolate, aggregate and apply custom logic for existing variable data to create direct input data as features.
- Random Forest training and model validation - The core step of model retraining, which takes refreshed data, retrains the model, and validates the model performance before persisting the model and the output files to external storage.
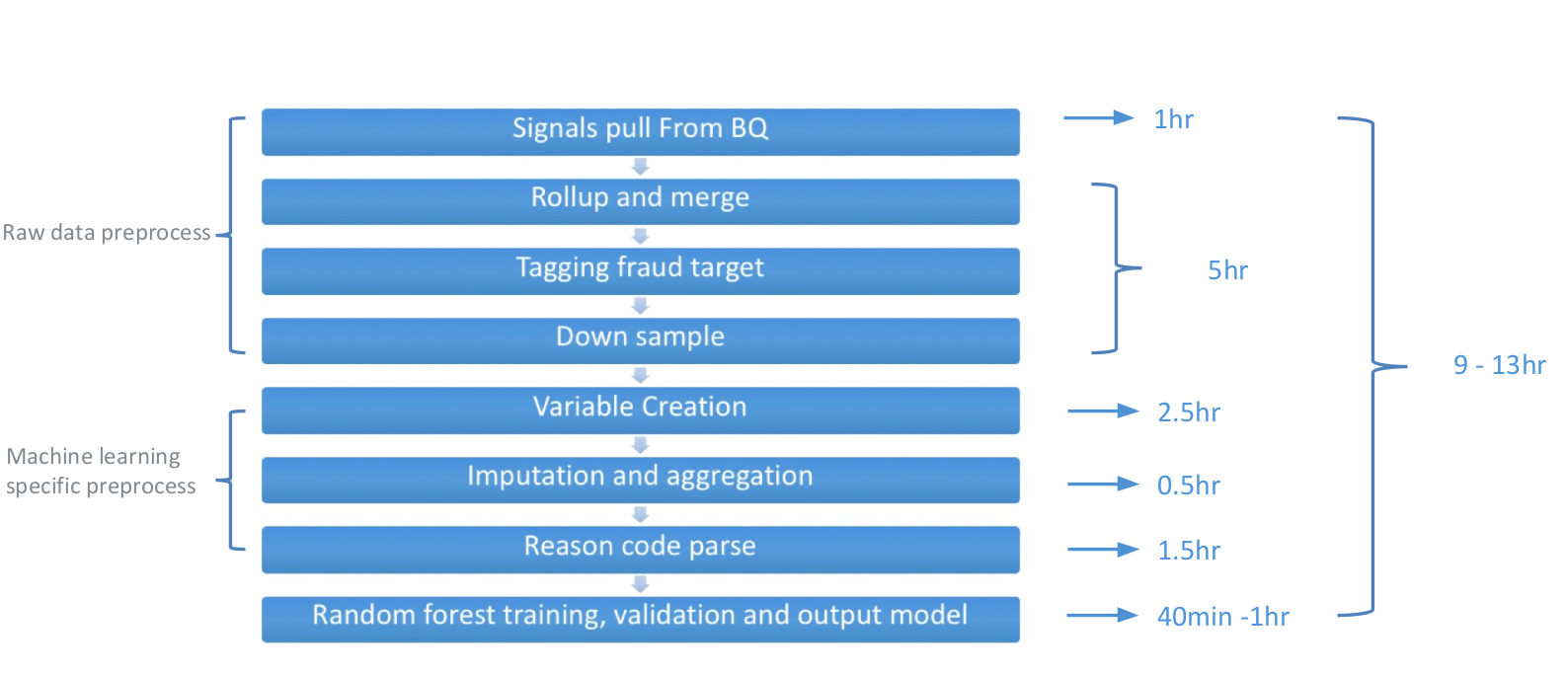
This approach has several drawbacks:
- Steps 2 and 3 handle pure data pre-processing tasks, but take more than 50% of the total processing time. However, they use the server’s local disk, which does not scale well. It’s also difficult to retry, resume or monitor progress in these steps.
- The single-server node becomes a bottleneck for the entire retraining process.
- The single-server instance makes the processing sequential, whereas a few steps in the process can actually be done in parallel.
- The single-server is also a single point of failure that requires the retrain process to restart from scratch. Recovering from both application and system level failures are expensive and manual.
- As WePay has several models to refresh and deploy, the multiplication factor of the slow process makes it quite challenging to refresh models on-demand to react to a changing fraud paradigm.
The New Approach
The new approach shuffles, improves and merges several steps of the retraining to achieve expected goals:
- Use BigQuery and UDF - At WePay we love BigQuery. It’s a great tool for our data volume and aggregation needs. With the infrastructure provided by our Data-Infra team, we are able to perform queries on existing datasets in BigQuery, and manage the permissions of various PII datasets as input for data pre-processing. We move the transposition work to much later in the process. BigQuery cuts the query and processing time by a few hours, which is significant in the overall process.
- Use AirFlow - We’ve documented our usage of Airflow for ETL. We also use Airflow for model training now. This enables us to manage well-monitored task executions defined by Airflow DAGs. It also makes it easier to restart when things fail. DAG dependencies are described as upstream/downstream dependencies between different operators. They enable us to see exactly where a retrain job failed. There is also a console in Airflow, which let’s us configure connections and credentials for various BigQuery and Cloud Storage configurations.
- Use Google Cloud Storage - Instead of using flat files, we switched to Google Cloud Storage for interim output of files or results between various Airflow operators. The output of the model is also deployed to production through Cloud Storage as well, utilizing Cloud Storage’s versioning and checksum features.
- Use no more flat files - Now we use BigQuery’s integration with Cloud Storage. This enables the transfer of data between various retrain tasks, instead of native file IO in Python code. It is also easier to retry when failures occur, and manage access to the data through the standard Google Cloud permissions, instead of managing access control for the specific single-server node in the old approach.
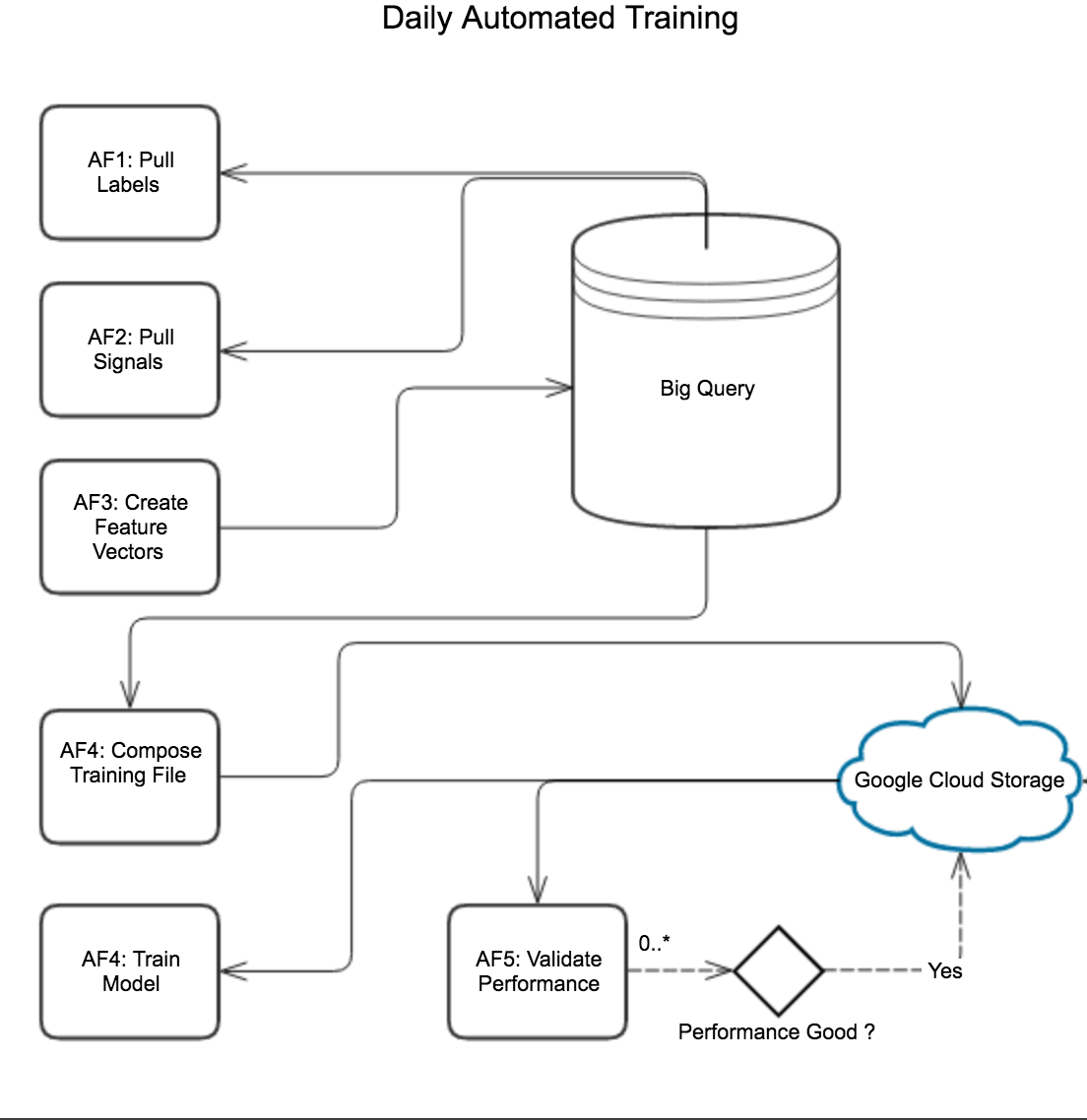
Conclusion
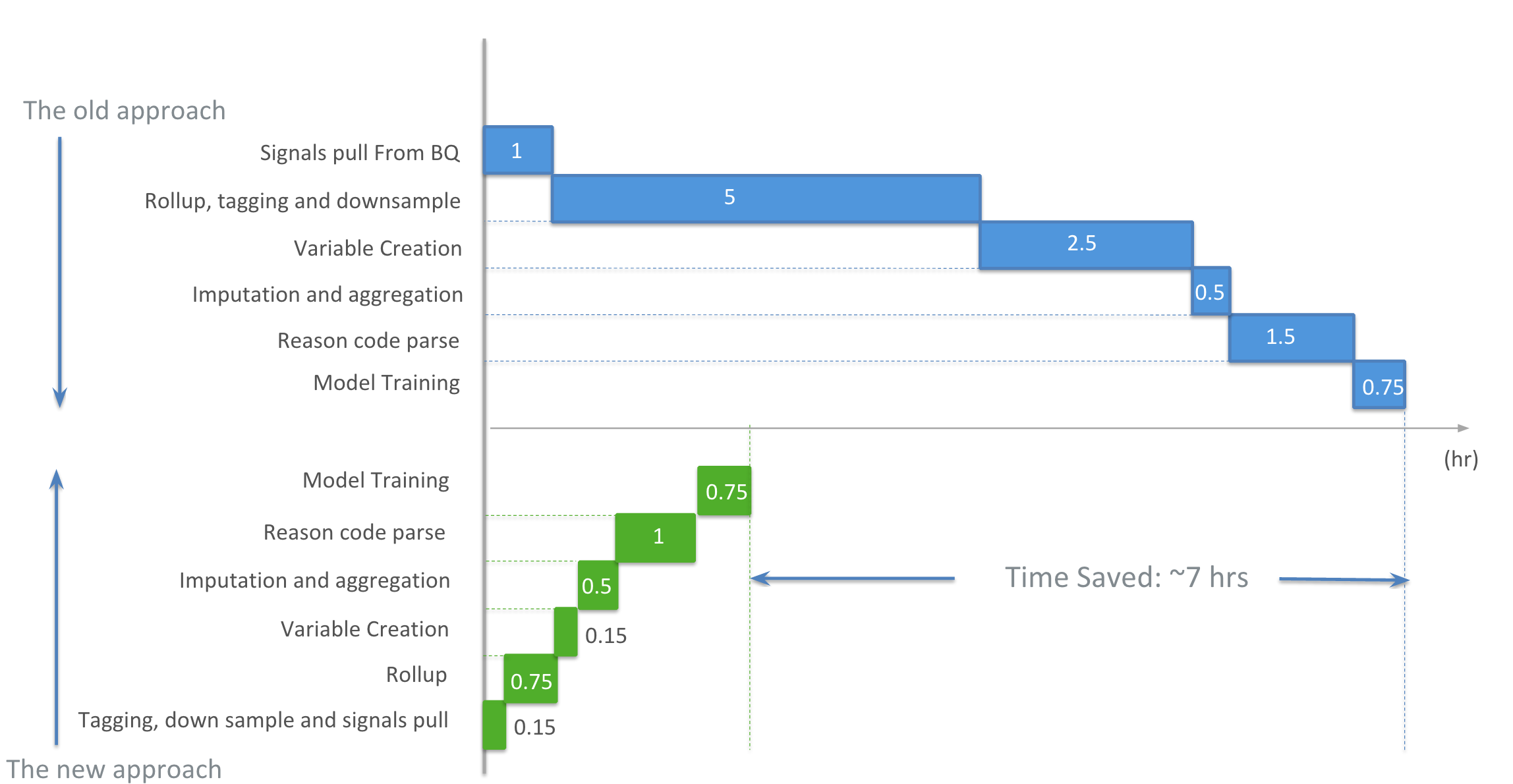
With the new approach tested in various environments, we are able to reduce overall processing time by over 70% for the entire data processing and machine learning pipeline. It eliminates the performance bottlenecks and single point of failure in the old approach, and distributes computing loads to various Cloud based services including BigQuery, Cloud Storage and Airflow. All of this is easily managed through the Airflow UI console.
The lift on business value is also obvious, as we are able to retrain various machine learning models much faster and in parallel, this will make our fraud detection and risk management service react much faster to changing fraud patterns.
Thanks to the guidance and technical direction from my mentors in the Risk team: Matthew Chen and Yaqi Tao, and my manager Shyam Maddali
About the author
At the time of writing, I am a graduate student of University of Southern California, where I am pursuing a degree of M.S. in Computer Science. As a member of the risk engineering team at WePay, my internship project was to automate machine learning models retraining.