
Loading data from Kafka into BigQuery with Kafka Connect
WePay recently released an open-source Kafka-BigQuery Connector on GitHub. We’ve decided to celebrate with a blog post detailing what exactly a Kafka Connector is, how we implemented ours, and why we needed one in the first place. Enjoy!
Tracking events at WePay
Handling and storing tracking events (logins, payments, account changes, etc.) at WePay used to be messy. We didn’t have a unified storage location for them and used a combination of MySQL, log files, and other locations. We also couldn’t run heavy-duty analytics on some of the larger stores of tracking events (see BigQuery at WePay for more details). Since we wanted to begin observing tracking events with higher granularity at the start of the summer, it seemed like a good time for the data infrastructure team to perform an overhaul of the existing system before becoming too reliant on it. We elected to use Apache Kafka as an aggregator for all of our tracking events, and then load them into Google BigQuery for storage and analytics.
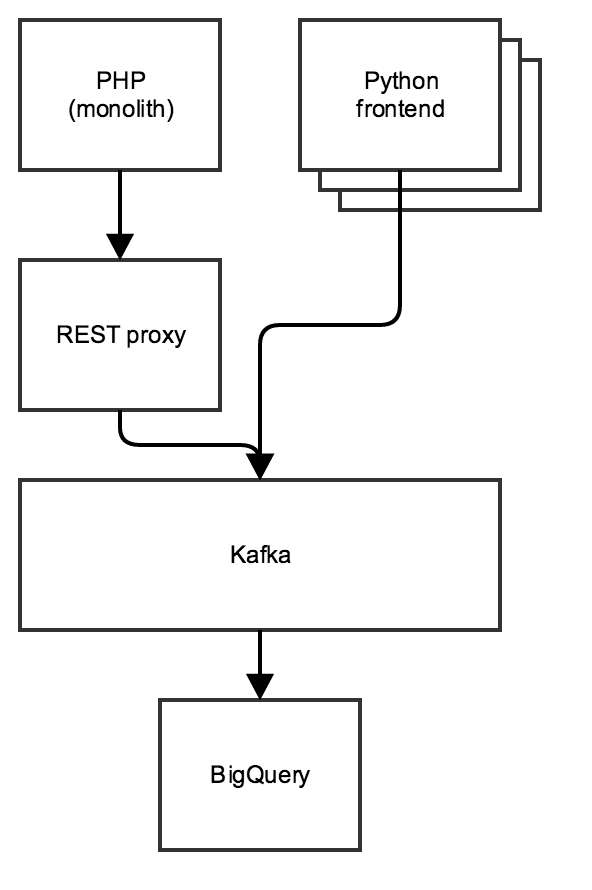
Our tracking pipeline consists of several front-ends emitting tracking events as things happen. One front-end is a legacy PHP system, and the rest are newer front-ends written in Python. The PHP front-end uses Confluent’s REST proxy service to send events, while the Python front end uses Confluent’s Python Kafka client. All of these systems are run inside Google Compute Engine. We’ll save the details of this pipeline for a future post.
What is a Kafka Connector?
Kafka Connect is a framework that runs connectors that move data in and out of Apache Kafka, and we’ve decided to use it for the job of loading tracking events stored in Kafka into BigQuery. Putting it into action in our pipeline involved developing our newly-open-sourced Kafka-BigQuery Connector, which allows users to stream data from Kafka straight into BigQuery with sub-minute latency via the Kafka Connect framework.
Kafka Connect is designed to make it easy to move data between Kafka and other data systems (caches, databases, document stores, key-value stores, etc). Using it to read from Kafka (and write to somewhere else) involves implementing what Kafka Connect refers to as a connector, or more specifically, a sink connector. When Kafka Connect is run with a sink connector, it continuously streams data from Kafka to send to the connector. If any new data is available, it gets converted into a versatile record format and passed to the connector, which can then perform some buffering but is ultimately responsible for writing it to whatever external system it’s designed for (such as BigQuery). Thanks to Kafka’s ability to track offsets, if the connector fails to complete a write for any reason, it can simply announce its failure by throwing an exception and Kafka Connect will give the same data again to the connector to write, helping make sure that no data gets skipped over.
Streaming into BigQuery
BigQuery has an idiomatic Java API client in progress that’s currently in the alpha phase of design. This client can be used to stream writes into BigQuery in real time. The writes show up in BigQuery surprisingly fast (a matter of seconds). For the most part, working with the library has been fine, and the biggest issues that have come up have had to do with their streaming data quotas, which are the same regardless of how data is sent to BigQuery.
Design
A sink connector isn’t a complicated thing. It takes data—actually, is given data—from one place and writes it to another. Writing one is as straightforward as implementing the SinkConnector and SinkTask abstract classes. Once those are taken care of, the Kafka Connect framework will use them to scale automatically, making for one less thing anyone writing a Kafka connector has to worry about. The role of the SinkConnector is to initialize any resources necessary for writing, such as creating tables that don’t yet exist in BigQuery, and then delegate configuration settings appropriately to one or several SinkTasks, which then do all of the actual data transferal via put and flush methods.
public abstract class SinkTask {
abstract void flush(Map<TopicPartition, OffsetAndMetadata> offsets);
abstract void put(Collection<SinkRecord> records);
abstract void start(Map<String,String> props);
abstract void stop();
abstract String version();
}
Any complexity in the implementation of a sink connector arises solely out of the requirements of the destination, and the restrictions of the source. I’ve included an example of each.
Record/Schema Conversion
Kafka Connect gives data to the connector in a special SinkRecord object. This record contains, among other things, an object containing the value of the data it is meant to transport and a schema detailing the format of the value. Unfortunately, this is not the format that BigQuery requires when performing insertions via their Java client; they have their own schema class, and since it is ultimately a database, the format for their rows is just a Map from Strings to Objects (with subtle differences in how byte arrays, structs, and some other types of data were handled). So the first step of writing the connector was to write code that would convert Kafka Connect records and schemas into BigQuery format.
Dynamic Schema Updates
BigQuery expects tables to already exist when an insertion request is made. When it receives an insert, it checks the format of each row to make sure that all required columns are there and of the proper type, and then either ignores or returns an error on any columns that don’t belong to the table based on configurable parameters included with the request. This means that if the format of the stream of data destined to arrive at a single table suddenly changes, everything will start breaking. Given that we may want to add on new fields to our tracking schema someday and not have to create new Kafka topics and/or BigQuery tables to handle the new data, that isn’t really an option.
BigQuery does allow backwards-compatible table schema updates, but knowing when to perform them and how to get the updated schemas is somewhat tricky. On the first front, we decided that it would simply be too expensive to verify the content of every record on the connector side, so we just decided to wantonly send everything we got to BigQuery, and handle the corresponding error message should any inserted rows not match their expected formats. On the second front, we opted to integrate the connector with the Confluent Platform’s Schema Registry tool, which allows schemas for data to be stored and updated with configurable compatibility settings (forwards, backwards, both, none). All the connector had to do was use their existing Java client to send a request to the registry, translate the stored Avro schema into a Kafka Connect schema (using tools provided by Confluent), then translate the Kafka Connect schema into a BigQuery schema. Now, if the dynamic table schema update option is enabled on the connector, it can automatically update existing tables in BigQuery to their newest versions in the Schema Registry.
It should be noted that, in order to avoid forcing users of the connector to rely on Schema Registry, we plan to remove dependency on it in the future while still supporting automatic table creation and schema updates. However, that patch is still a ways away, and we’ve encountered no problems thus far using the connector as-is with its integration with Schema Registry.
Conclusion
Check out our GitHub repository for more information how to get started with the Kafka-BigQuery Connector. Patches are encouraged!
About the author
At the time of writing, I am in between my third and fourth years at Oberlin College, where I am pursuing degrees in cello performance and computer science. As a member of the data infrastructure team at WePay, my project as an intern was to implement the Kakfa-BigQuery Connector.