
Sidecars and DaemonSets: Battle of containerization patterns
In our recent post, using Linkerd as a service mesh proxy, we kickstarted a series documenting WePay Engineering’s look at technologies and patterns for introducing service mesh and gRPC to our infrastructure.
For the second part of the series, we’re going to focus on some containerization patterns we’ve been experimenting with and using in Google Kubernetes Engine (GKE). Specifically, we have used the sidecar and DaemonSet patterns when introducing infrastructure services (service mesh proxies, and other agents) to a Kubernetes cluster with a Service Oriented Architecture (SOA).
Battleground
A long time ago, in a few Kubernetes clusters far, far away, many microservices were born in Google Cloud Platform projects that required assistance from the infrastructure for logging, request routing, metrics, and other similar toolsets or processes. Over time, the data vended by each microservice have either been consumed by other microservices or by site reliability engineers, development tools, and/or product development engineers.
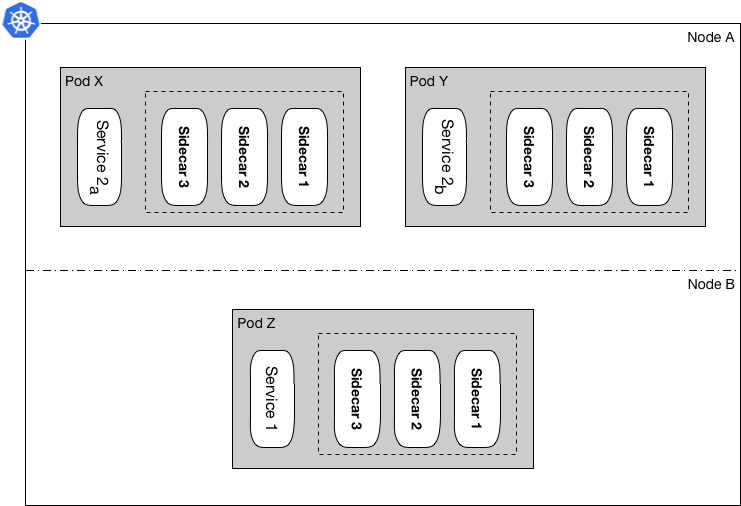
Figure 1: Original container layout in our Kubernetes clusters
Each microservice that is added to these clusters, can have a number of replicas, where that number can be one or many. Figure 1 demonstrates an example infrastructure including a couple of microservices, accompanied by multiple sidecars for each of their replicas. For the people developing, maintaining, monitoring, or consuming these microservices, many things including reliability, maintainability, and lifecycle are very important.
Below, we’re going to dive deeper into the Sidecar and DaemonSet container patterns based on these requirements, and compare them with each other. Specifically, we’re going to focus on machine resource usage, sidecar (agent) lifecycle, and request latency across different applications in our Kubernetes clusters, the home for our microservices.
My resources, oh no!
When DaemonSet and sidecar patterns are compared, the first thing that comes to mind is that in production grade infrastructure, the Sidecar pattern ends up taking up a lot more machine resources than the DaemonSet pattern. Overall, not all infrastructure services or agents need to be side-by-side our main applications. So we’re going to look at some cases where we dedicate our infrastructure agents to more than just one main application container in a Kubernetes cluster at WePay.
In infrastructures where under ten microservices are running, this might not be an immediate problem, but as the infrastructure matures and the business grows, ten becomes twenty or thirty. Realistically, one could end up owning multiple clusters with more than a few dozen or even hundreds of microservices to monitor and trace.
If we consider the infrastructure shown in Figure 1 with three microservices, we end up with fifteen containers, with only 20% of them being microservice containers. Now, if we decide to introduce more infrastructure agents to the pool, the number of containers and resources used changes as follows:
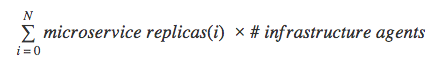
Function 1: Sum of all containers in the infrastructure with Sidecar pattern
(N is the number of microservices)
Using the equation in Function 1 and adding a new agent, we go from fifteen containers to twenty for just three microservices. Additionally, we’ve noticed resource problems become even more challenging when any of the agents are implemented in resource heavy languages like Java, where, for example, memory usage tends to grow large over time.
To take a real life example, Buoyant has recently taken the initiative to migrate from Scala and JVM (Linkerd) to Rust (Conduit) to make service mesh proxying lighter and faster when running in a Kubernetes or any other containerized infrastructure.
Based on our experience with resource management of containers, we’ve been focusing on studying the resource utilization and footprint for any new agents we intend to add to the pool of containers in our infrastructure.
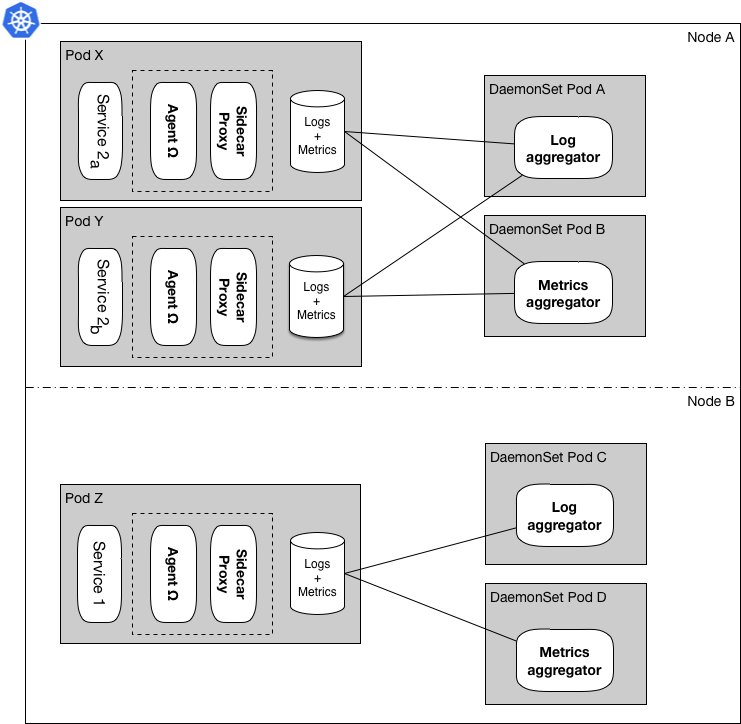
Figure 2: Some agents refactored to use the DaemonSet pattern
One of the more important lessons we’ve learned as we’ve introduced new agents to our clusters over time is that some agents can handle more than just one microservice container at a time and oversee a pool of containers. For example, initially every single microservice container had a log aggregator sidecar that would stream that microservice’s logs to a central log stack, but as our clusters grew, we refactored those aggregators to the pattern shown in Figure 2.
In this figure, the logging and metrics aggregator agents are aggregating logs and metrics data for all the service containers in their assigned node as opposed to a one-to-one relationship in Figure 1, while the sidecar proxy and Agent Ω continue to hold a one-to-one relationship with their microservice containers. Using this hybrid pattern we’ve reduced container usage significantly, and from the earlier example the sum of all containers changes to sixteen from twenty:
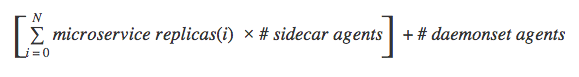
Function 2: Sum of all containers in the infrastructure with DaemonSet pattern
(N is the number of microservices)
That continues to show a significant resource usage improvement for us as we add new infrastructure agents to our production environment, where there are more than a few dozen microservices.
Considering lifecycles
At WePay we follow the agile software development model to create our products and tools, so we end up developing, reviewing/updating, deploying, and repeating this cycle until the piece of software we’re developing is either no longer used or decommissioned. The same cycle is true for all the agents used in the infrastructure, no matter if the agent is an open-source project or built in-house, and any improvement to any of the agents will require a rollout to all active environments.
Over the course of implementing our application containers and deploying our agents, we’ve come to realize that maintaining the Sidecar pattern is not always a good practice and might be an overkill for two main reasons. The first issue was mentioned above, wasted machine resources, and the second is the difference between the lifecycle of agent and microservice containers. In other words, while closely tying together some containers might make sense, that pattern was shown not to be required for all of our containers deployed to a cluster.
For example as mentioned in the previous post in the series, a service mesh proxy is used to route requests from a source to a destination, and Figure 3 below shows this with the Sidecar pattern.
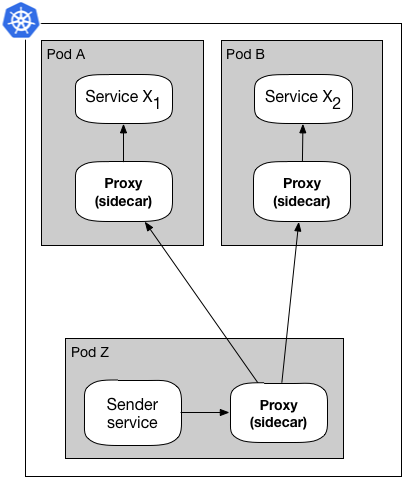
Figure 3: Sidecar pattern with mesh proxy sidecar
The Sender service sends its request to the sidecar proxy next to it, that proxy through discovery chooses a destination proxy, and eventually, the destination proxy, for example in Pod A, forwards the request to the Service X**1 container. In Figure 4, the same feature is achieved with the DaemoSet pattern:
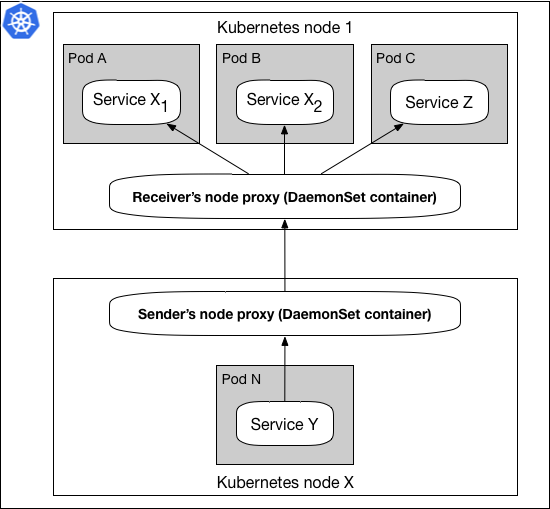
Figure 4: DaemonSet pattern with mesh proxy node containers
Whether any of these proxies are next to an application container or not, that proxy will still be able to accomplish its purpose, meaning that its logic and execution is independent of any application container (we will talk about the network scope in the next section).
This holds true for all containerized and independent agents built to be installed in a Kubernetes cluster. This of course assumes no feature or access to data is lost when transitioning between any of the Sidecar and DaemonSet patterns.
The lifecycle challenge in the Sidecar pattern is big enough that we’re starting to see service stacks offer tools, like the sidecar-injector in Istio and linkerd-inject in the Linkerd project, to allow configuring proxy sidecars from a single place. It is worth mentioning that centralizing configuration for sidecars only simplifies configuration, and does not address the interruption in the execution of the containers within the same Kubernetes Pod. In most cases, the entire pod needs to be recreated for all changes to take effect for the pod. In Figure 3, if the proxy (sidecar) needs to be updated, the entire pod must be restarted/recreated for that change to take effect. Meaning that all containers within Pod A will have to stop execution for recreation of a pod in place of Pod A.
However, If the lifecycle of these containers are separated, as in a DaemonSet setup, updating one container won’t interrupt the others execution, and lowers the risk of inadvertent issues and downtime. For example, in Figure 2 a Log aggregator upgrade in DaemonSet Pod C won’t interrupt execution of Service 1 in Pod Z, and that can come handy in various use cases.
Network distance and request grouping
Another major difference between using the patterns being discussed, is the distance between the data and the agents. Meaning the difference between the number of hops or redirects a request, sent or received by an agent, would have to go through for the same request in a Sidecar vs. DaemonSet setup.
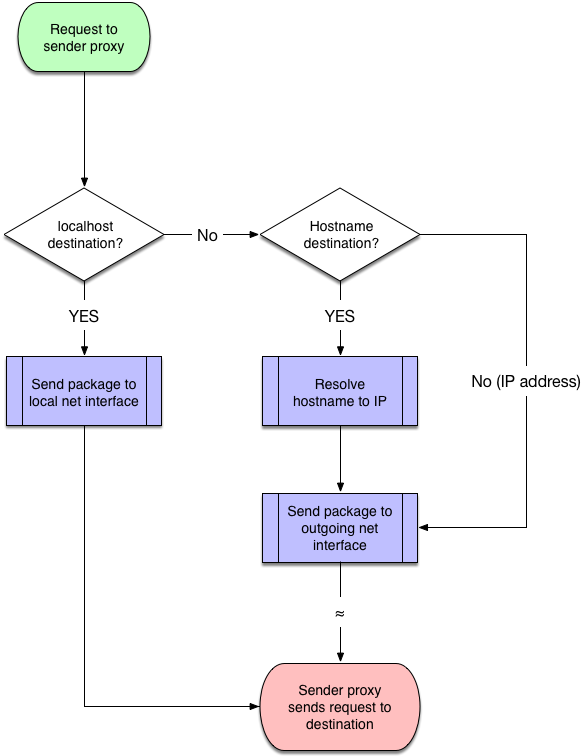
Figure 5: Local request (Sidecar) vs. non-local flow (DaemonSet)
As demonstrated in Figure 5, in a worst case scenario, a request sent to a sidecar container includes fewer steps and could result in faster transmission. In this case when a sender service sends a package and uses localhost to transmit that package to the destination, all that’s required for getting the package to a proxy is to be sent to the corresponding port in the same network space. On the other hand, when that same package is sent to a proxy using a hostname or IP, the transmission goes through a hostname resolution and also farther network travel, respectively, in addition to the localhost transmission steps.
In regards to latency, using high performing hostname resolvers and network transmitters the extra steps might be ignorable, but the network space and scope is a noticeable difference between the two containerization patterns.
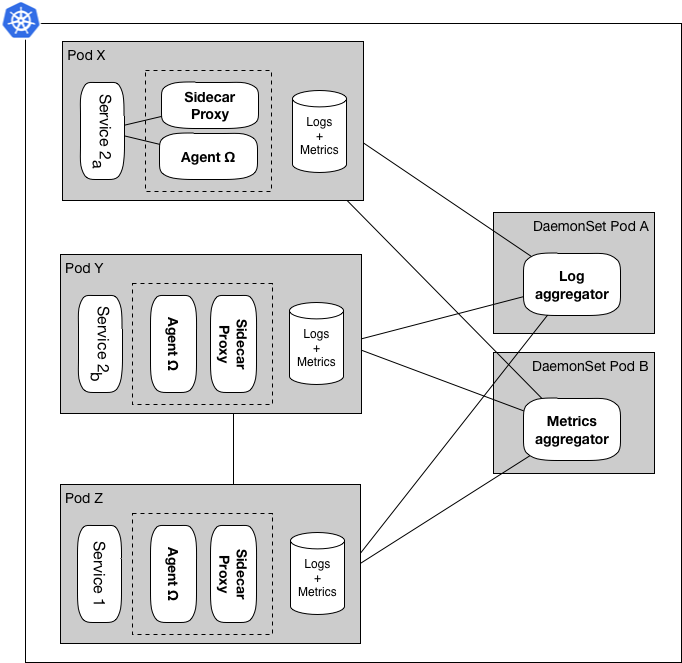
Figure 6: Group of requests in a DaemonSet and single concern for Sidecar
Figure 6 shows another comparison, request grouping, that we have taken into consideration in our studies. A DaemonSet container has to service all targeted containers in a cluster node, whereas a Sidecar container can only service focus on containers in its pod. This grouping might make sense for some agents, and not for others.
Putting it all together
There are a few important aspects in choosing between sidecar and DaemonSet patterns, but throughout the years the machine resource usage, lifecycle of agents and microservices, and request latency between different applications have been the focus point for us. Specifically, we have:
- Lowered the resource usage by using the DaemonSet pattern
- Made upgrading of applications and infrastructure agents easier where we could use DaemonSets
- and, have optimized latency between containers where necessary.
In the upcoming posts in the series we’re going to touch more on how we build our service mesh infrastructure to be highly available for our REST and gRPC applications. We are also going to take a look at how we build our gRPC applications at WePay using the infrastructure we’ve been describing to make things even faster, more reliable, and maintainable.