
Using Linkerd as a Service Mesh Proxy at WePay
In the upcoming months, we are going to write a series of posts documenting WePay Engineering’s journey from traditional load balancers to a service mesh on top of Google’s Kubernetes Engine (GKE).
In this first part of the series, we are going to take a look at some of the routing and load balancing options that we have used before, compare them with the services we have looked at as possible service mesh proxies, and how they’d change the way our infrastructure operates.
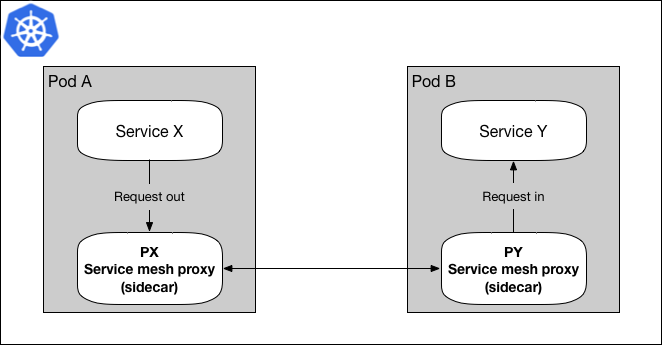
Figure 1: Data plane using sidecar proxy pattern
Figure 1 shows a simplified version of a data plane, in service mesh terms, where Service X is sending a request to Service Y via it’s sidecar proxy. Since Service X is sending the request through it’s proxy, the request is first passed to Service X’s proxy (PX), then sent to Service Y’s proxy (PY) before getting to the destination, Service Y. In most cases, PX finds PY through a service discovery service, e.g. Namerd.
Our meetup session about gRPC talks a bit about using this pattern for proxy load balancing.
In this post, to keep things simple, we’re going to focus on the data plane, and to simplify things further, we’re going to only talk about proxies using the sidecar pattern.
Side note: all technologies mentioned in this post are very sophisticated pieces of software that have been written by talented engineers and open sourced to be available for other companies with similar use cases. The comparisons below are solely based on WePay’s use cases and which technology fit those use cases best, and it’s not intended to the discredit other technologies mentioned.
Setting the stage
At WePay, we are currently running many microservices (Sx) in GKE. Some of these microservices talk to other microservices in the same data center, which looks something like this:
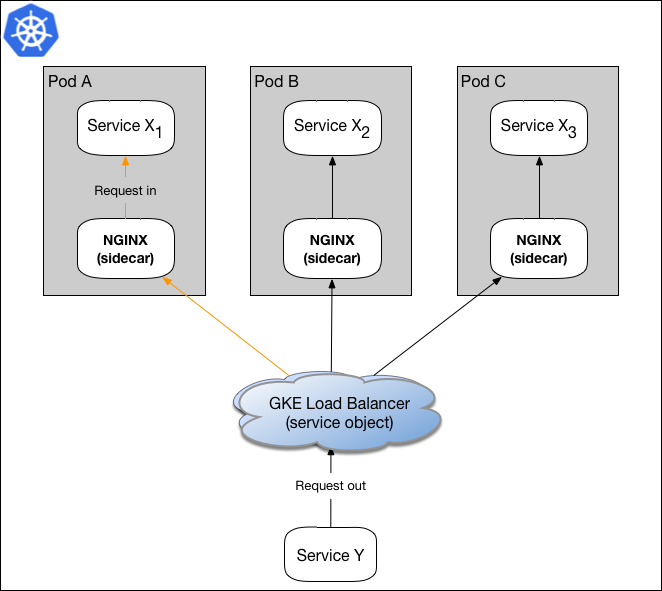
Figure 2: Simple load balancing using GKE and NGINX
In the model shown in figure 2, Service Y sends a request to Service X, and Kubernetes’ load balancing object does the load balancing for Service X by forwarding the request to X1’s NGINX sidecar. When NGINX receives the request, it terminates SSL and forwards the packet to X1.
As we have grown the number of microservices in our infrastructure in the past year or so, the following issues have proven to be very important to us, and in some ways, the motivation for our move to a service mesh:
- Smarter, performant, and concurrent load balancing
- Platform and protocol agnostic routing, with HTTP and HTTP/2 (with focus on gRPC) as requirements
- Application independent routing and tracing metrics
- Traffic security
Once we knew we wanted to migrate into a service mesh infrastructure, we looked at various different proxies for building our data plane. From the list, Envoy and Linkerd looked to be the closest to our interests, while offering a mature feature set at the same time.
Side note: At the time of research, NGINX had no service mesh support, but in an effort to support the service mesh infrastructure, NGINX has added Istio support. For the purpose of comparison, Envoy and NGINX fall in the same pool.
Better load balancing
Envoy and Linkerd both offer access to some of the more sophisticated load balancing algorithms, but Linkerd’s focus on performance tuning, and the platform’s usage of Finagle, made it an appealing choice for load balancing.
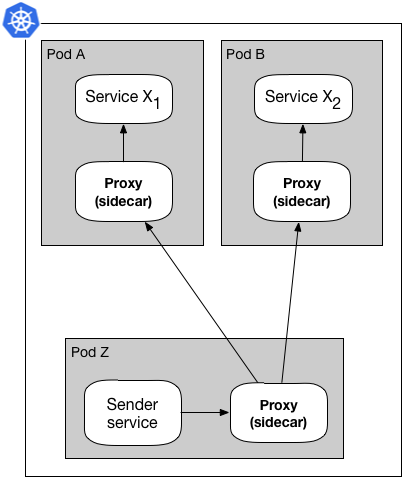
Figure 3: Sidecar proxy pattern handles load balancing
Figure 3 shows how a service mesh proxy handles the load balancing using a list of available destinations acquired through service discovery.
In addition to the basic load balancing features, Linkerd also allows pushing the load balancing closer to the edge of each Kubernetes node with support for Kubernetes DaemonSets. From a resource allocation perspective, this also lowers the cost of running the proxies in larger clusters, significantly.
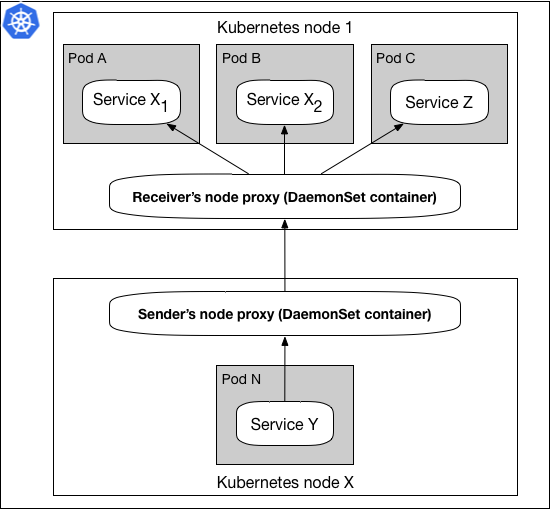
Figure 4: DaemonSet proxy pattern
In figure 4 the DaemonSet pattern shows each Kubernetes cluster nodes hosting one proxy. When Service Y sends a request to Service Z, the request is handed off to the Sender’s node proxy, where using service discovery, it forwards the request to Receiver’s node proxy, and eventually the package is delivered to Service Z. This pattern makes maintaining and configuring these proxies easier by separating the lifecycle of proxies from microservices running in the same cluster.
New protocols, same infrastructure
Back in 2017, when we were looking at improving our service to service communications with gRPC, Linkerd supported HTTP/2 and gRPC out of the box making it easier to migrate to a service mesh using Linkerd.
In addition, the ability to use both HTTP and HTTP/2 (gRPC) for any microservice, and the need for supporting multiple protocols at the same time in our infrastructure, meant that multi-protocol support had become a hard requirement for choosing a proxy for our infrastructure..
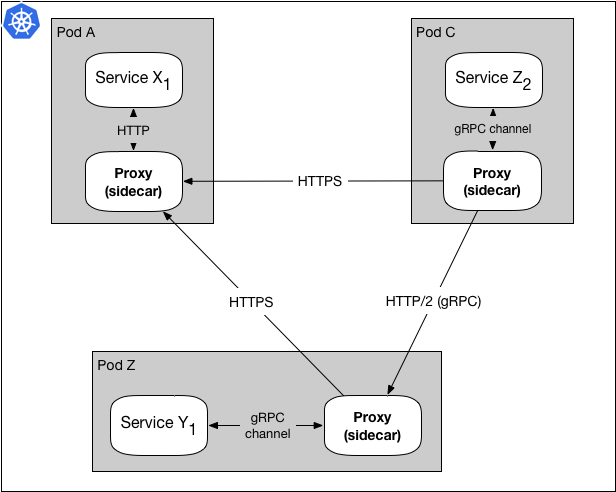
Figure 5: The proxy accepts and forwards both gRPC and HTTP in the same setup
This diagram shows how some requests are using HTTP while others are using HTTP/2. Being able to use multiple protocols with the same infrastructure configuration proven to be a critical feature when we planned our migration from HTTP to HTTP/2 (gRPC). During a migration, we have some services talking to each other over HTTP, while others are communicating over HTTP/2. Figure 5 is imagining the infrastructure as the rollout happens over time. In a future post we will dive deeper into how our microservices send and receive different types of payloads in our infrastructure, e.g. REST, Protobufs, etc.
Today, most service mesh proxies, including Envoy, handle the latest protocols like HTTP, HTTP/2, and others.
I can haz metrics
In our infrastructure we make use of Prometheus to monitor Kubernetes, microservices, and other internal services. Envoy requires an extra step to make use of Prometheus, but with the ready-to-use Prometheus telemetry plugin from Linkerd, it was easier for us to get up and running with graphs without the need for extra services gluing service mesh proxies to our visualization dashboard:

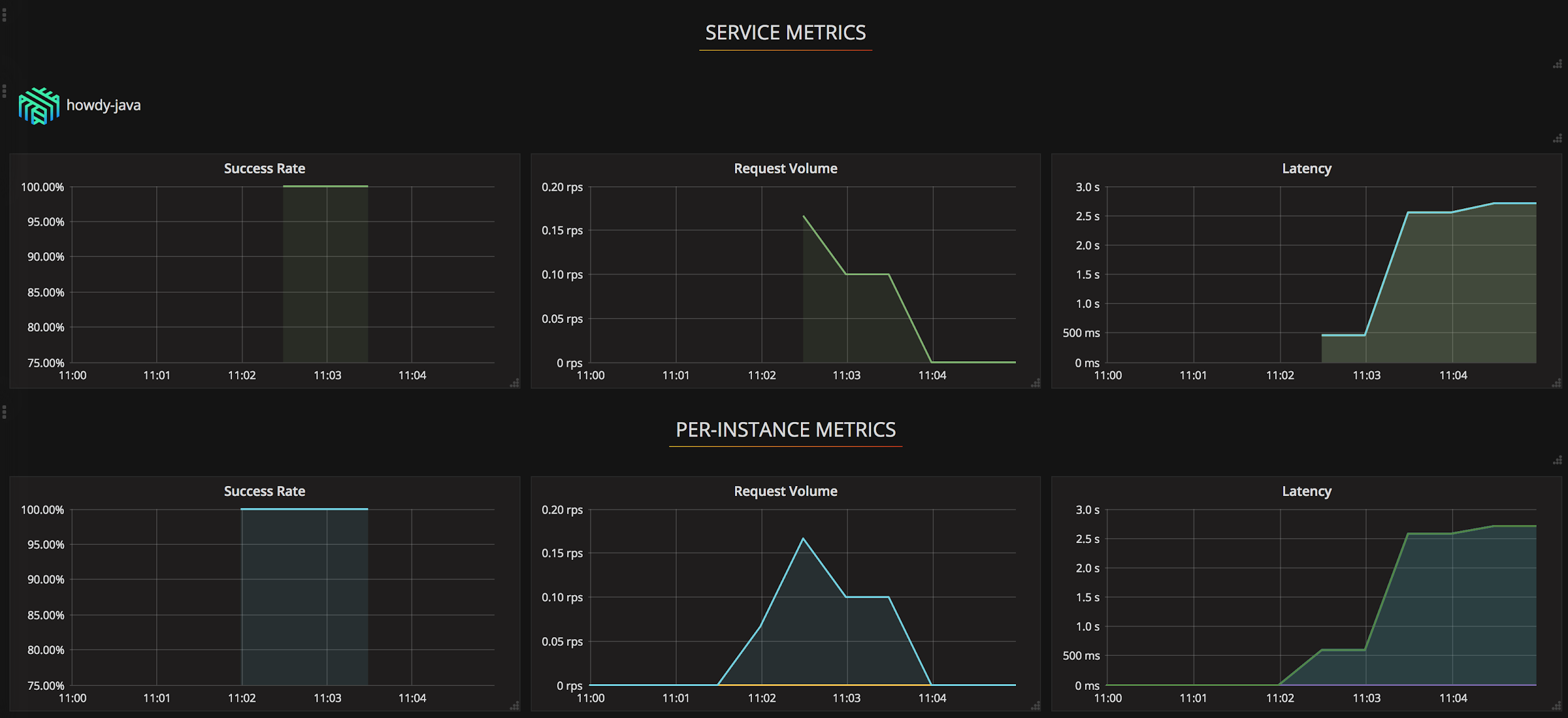
Figure 6: Cluster and application level view of proxy metrics
The sample dashboards in figure 6 show the global, per-microservice, and per-proxy traffic in one place for better visibility into what’s going through the infrastructure, in a DaemonSet proxy pattern.
One of the other convenient parts of using Linkerd is the range of metrics the proxy comes with out of the box. In addition, Linkerd also makes it easier to write custom plugins to control, for example, the retry mechanism using those custom metrics. So any specific metrics, alerting, and monitoring can be retro fitted to meet the need of the infrastructure that’s running service mesh.
Crank it up, security that is
Most proxies nowadays support various proxy to proxy encryption and authorization methods, and with Linkerd we have the ability to go even further when used with the sidecar pattern. Using the sidecar pattern, we’re able to use the per-service authorization in Linkerd, which gives us the ability to maximize infrastructure security, where and when applicable.
One thing that does work differently in an environment setup with the sidecar proxy pattern is per-service TLS certificates for SSL handshakes.
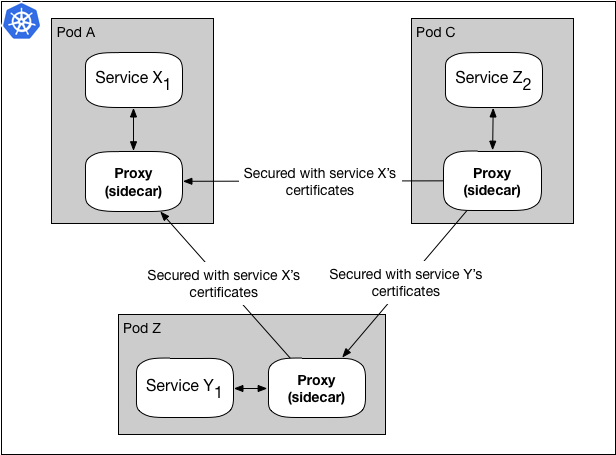
Figure 7: Per-service TLS certificates used for SSL handshakes
Figure 7 shows a Linkerd proxy for Service Z using Service X’s certificates when sending a request to Service X, and using Service Y’s certificates when sending a request to Service Y. This gives us the ability to maintain, update, and change SSL certificates for each service independent of each other, and also increase the security of our microservices.
This feature can be useful for some setups, but quite overkill for some others, so having the ability to choose one over the other is a nice feature.
Conclusion
Based on the infrastructure requirements and improvements in mind, we decided to pick Linkerd for our technology stack.
Using Linkerd, we can have the reliability that we need, introduce new protocols to our infrastructure for our microservices to use, have more visibility into our service traffic, and tweak security as we see fit.
In the upcoming blogs in this series, we’re going to talk about different parts of a service mesh architecture, and how they apply to WePay’s architecture.