
A Purposeful ProtoBuf Repository
In 2018, the Platform team at WePay integrated and released the first version of WePay’s internal gRPC ecosystem and toolchain to the WePay developers for a smooth migration from RESTful APIs to gRPC.
Shifting, adopting, and migrating large portions of a platform or infrastructure, such as adopting gRPC, has required establishing new standards and defining new processes that establish boundaries and guidelines. At WePay engineering, we are advocates of open source software, and we contribute back to the community as much as our internal use cases enable us to, but there are also components that need to be architected internally and specifically for the technology stack at hand.
In the case of gRPC, we had to implement processes along with a repository for how Protocol Buffers (ProtoBufs) are defined, stored, and distributed internally at WePay. For the purpose of this post, this repository is where digestible ProtoBuf definitions are stored, and consumed by different systems.
Back in 2018, based on how our developers collaborated on defining their private and common ProtoBufs, we decided to maintain a service-based ProtoBuf repository that would allow service owners to define their gRPC APIs. In addition, service owners were also allowed to use a common space in the repository to define ProtoBufs that may be used by other services in the same repository, e.g. address definition for users, or request/response structure for internal service APIs. In theory, these common definitions were owned by the service that created them, but were reusable by other service(s) that might be operating in a similar space in the infrastructure:
service-a/
service_a_commons.proto
requests.proto
responses.proto
service.proto
service-b/
service_b_commons.proto
requests.proto
responses.proto
service.proto
commons/
service-a/
commons.proto
Code 1: A service-based ProtoBuf repository structure
with services and a single common package
In Code 1, Service A defines common definitions that may be used by other services in commons/service-a/commons.proto. The same also applies to all other services in the repository, e.g. commons/service-a/commons.proto for Service B. Common definitions that were implemented under a service space, e.g. service-a/service_a_commons.proto, were meant to be privately used, independent of the common definitions under commons/. Note that privateness of ProtoBuf definitions in this hierarchy are only suggested to ProtoBuf developers through the structure in Code 1, and there are no processes that restrict other parts of the repository from using the “private” definitions.
This pattern started to become challenging over time, primarily with respect to ownership and purpose, and that’s what I’ll be talking about in this post.
Working with Protocol Buffers
At the very high level, there are some main ProtoBuf principles we use as reference:
- Definitions are stored centrally.
- gRPC clients and servers consume ProtoBuf definitions at build time for a distributed generation.
- Tooling is standardized, centralized (CI/CD), and polyglot, e.g. linting, generation, validation, etc. for programming languages used in production services.
- ProtoBuf definition changes to be backwards compatible, ONLY.
These principles shape our ProtoBuf implementation and delivery pipeline:
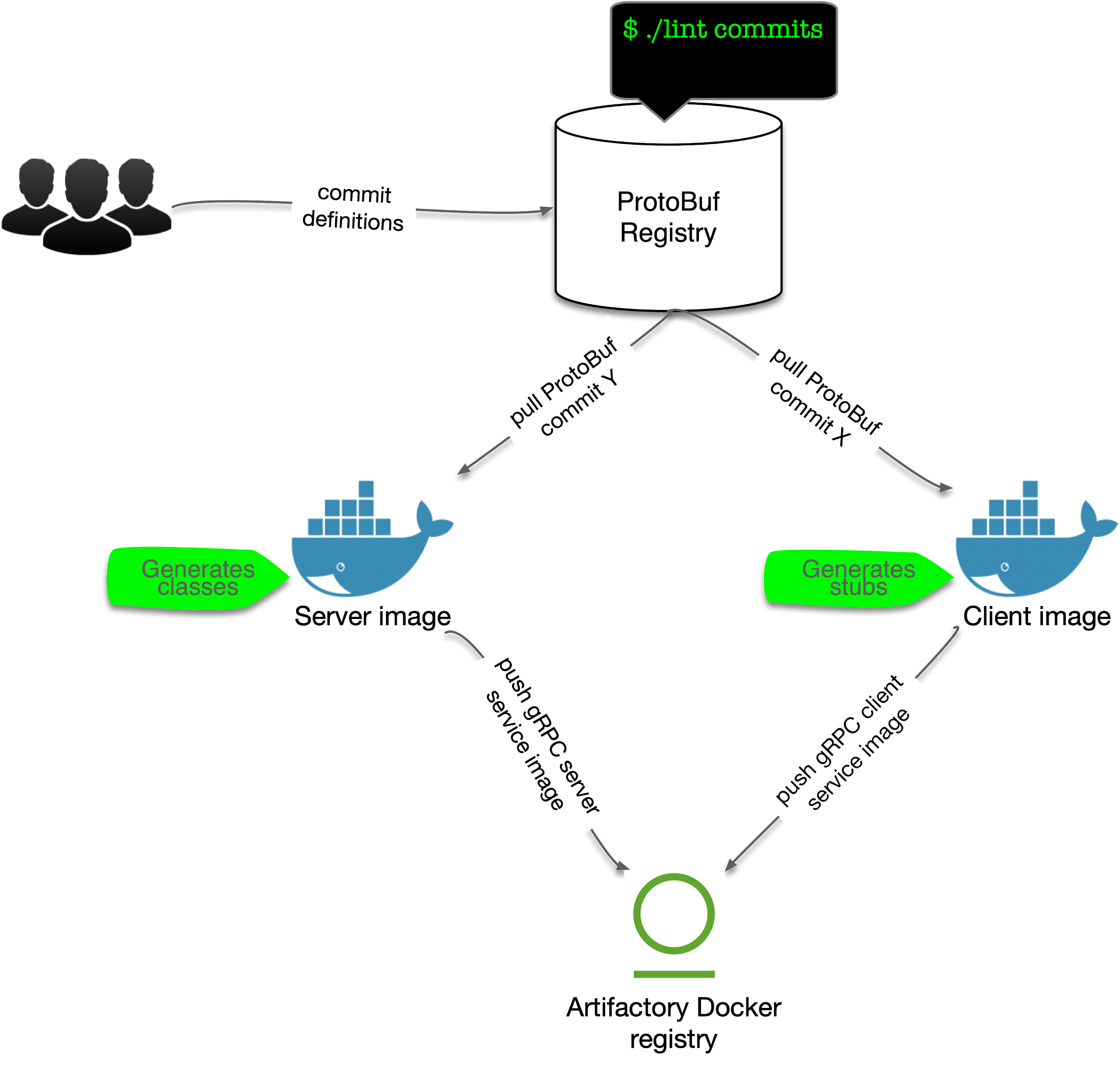
Figure 1: ProtoBuf definitions lifecycle flow
At WePay, ProtoBuf is primarily used for defining gRPC APIs and data used in the requests and responses in these APIs. I’ll talk more about how we’re expanding our use cases in a bit.
Figure 1 shows the high-level lifecycle of our ProtoBuf definitions from definition to consumption by the gRPC clients and servers. As mentioned in one of our previous posts, we use prototool to validate ProtoBuf changes that are proposed against our ProtoBuf repository. Once changes are validated, they are merged into the main, master, branch where client and server services pull them for ProtoBuf generation, stubs and/or classes, that are used in the final service images.
While we’ve benefited from defining our gRPC services in ProtoBuf, i.e. Code 1, it was difficult to use the same ProtoBuf repository for hosting other possible ProtoBuf use cases, e.g. migrating more complex JSON schemas, defining Kafka events (ported from Avro), etc, in additions to the pain points mentioned earlier around purpose and ownership.
From Flat to Purpose
In our experience, some of the main challenges with a service-based ProtoBuf repositories were:
- Service names didn’t necessarily communicate the purpose of the ProtoBuf definitions with the other tenants of the repository.
- Service definitions didn’t clearly define or guide developer ownership as engineering functions changed.
- The service-based structure didn’t clearly define a purpose for the commonly used ProtoBuf definitions.
- …and the service-based structure made tooling automation and configuration difficult.
Which, at a high level, translated to the need for:
- Building a unified ProtoBuf repository for hosting all service based data definitions, e.g. migrations from JSON and Avro definitions, and defining more complex ProtoBufs.
- Eliminating the tight coupling between services or teams and the data definitions.
- Introducing purposeful base packages to allow for organically shaping the definitions into primitive types, bounded canonical data models with business context, and service interfaces.
Using these principles, the repository shaped into three base packages with three clear purposes:
/
rpc/
service-1/
requests.proto
responses.proto
service.proto
service-2/
service-aggregator-1/
agg_purp_1_service.proto
agg_purp_2_service.proto
agg_purp_3_service.proto
service-3/
service-aggregator-2/
model/
card_present/
devtools/
<business_context>_reporting/
pagination/
type/
address.proto
card_brand.proto
Code 2: `rpc`, `model`, and `type` base WePay ProtoBuf packages
At the root of Code 2, /type, /model, and /rpc packages store ProtoBuf definitions with their own clear purpose, ordered from the least (WePay primitive types) to most complexity. Each package builds on top of a lower complexity package to eventually expose a series of data as an API to other services in the infrastructure. Use cases like Kafka events follow the same principle, but instead of exposing an API, the events are defined in models, i.e. /model.
These packages provide WePay developers with:
/rpc, which allows all services, and service API aggregators or gateways, to define rpcs and use /model for complex/shared data used in request or response definitions./model, which provides a space for defining complex/shared canonical data models (CDM) with clear business context independent of teams or services./type, which creates primitive ProtoBuf definitions as fundamental building blocks for the repository, and are defined by the WePay Engineering organization. We call these WePay Primitive Types (WPT).
In addition to these packages, the Well-Known ProtoBuf Types are also used across the repository for defining more fundamental fields. In theory, WPTs are very similar to WKTs in that both types build the foundation for all other ProtoBuf definitions, but WPTs are scoped to define payment specific types that can be used across the infrastructure, e.g. currency codes and card types or brands.
Using this dedicated hierarchy, we’ve been able to define the data flow between services with respect to business needs, allowing clear ownership over more complex and shared data definitions, while opening the door for other serialization formats to be migrated to ProtoBuf for a unified data serialization format across the infrastructure.
Creator Ownership
Another idea behind creating a purposeful ProtoBuf repository was that with the right guardrails and guidelines, creators of ProtoBuf definitions would be able to clearly define their ownership, and be automatically notified when there are proposed changes for what they own.
At WePay, we use Atlassian’s Bitbucket Server for storing our source code, and for our ProtoBuf repository we used a process that was internally created on top of Adaptavist’s ScriptRunner for Bitbucket Server for defining code ownership. Using this process we built a YAML configuration for defining ProtoBuf ownership in pull requests:
#### package and primitive type specific ownership
- filePaths:
- "glob:/*"
- "glob:/model/*"
- "glob:/rpc/*"
- "glob:/type/**"
errorMessage: "Consult new packages with the Platform team."
groups:
- "<bb-platform-1-group>"
- "<bb-platform-2-group>"
#### model specific ownership
- filePaths: # Card Present team
- "glob:/model/card_present/**"
errorMessage: "Card Present team should be consulted."
groups:
- "<bb-cpe-group>"
- filePaths: # DevTools team
- "glob:/model/devtools/**"
errorMessage: "DevTools team should be consulted."
groups:
- "<bb-devtools-group>"
#### rpc specific ownership
- filePaths: # Reporting team
- "glob:/rpc/rep-service-1/**"
- "glob:/rpc/rep_gateway-1/**"
- "glob:/rpc/rep_gateway-2/**"
errorMessage: "Reporting team should be consulted."
groups:
- "<bb-rep-group>"
Code 3: Developers and their respective team
own their ProtoBuf definitions
A single team, Platform, owns the code ownership configuration in Code 3, which is stored in a separate configuration repository, and developers and their group own their respective ProtoBuf space in the central ProtoBuf repository. Different spaces may have multiple groups as owners, but no new space will be left without an owner based on the package and primitive type ownership from the configuration in Code 3.
This provides autonomy to the ProtoBuf definition creators, and automatically notifies them when changes are being proposed against their creation. This also promotes communication between teams developing in a similar space or in need of creating definitions for the entire WePay Engineering organization.
We think that by defining the principles mentioned in the beginning of this post and moving to the new purposeful ProtoBuf repository with full creator ownership, we’ve made developer onboarding to the ProtoBuf world simpler at WePay, while allowing for a better maintenance and coherent growth path for all the definitions stored in the repository. Additionally, this standardization has also made it simpler to provide polyglot tooling for all the systems that use ProtoBuf definitions at WePay; implementation to consumption.
We will continue to evolve this process as we migrate other use cases to it, and we will share more updates on this thread as we run into more interesting findings.