

Migrating APIs from REST to gRPC at WePay
In the previous posts in our service mesh series, we talked about how we’ve set up our service mesh infrastructure to modernize our microservice and load balancing architecture, and how we ensure the service mesh infrastructure is highly available so we can use all of its great features at all times with no interruptions.
In this post, we’re going to shift our attention toward how our microservices are using service mesh to communicate with one another. Specifically, what payloads are used for the requests sent between them, and how we’ve migrated from one to another. We’re going to compare our current Representational State Transfer (REST) based payloads to a high-performance Remote Procedure Call (gRPC) framework and go over the challenges of adopting, using, and migrating to gRPC.
From RESTful to gRPC
As mentioned in our previous posts, we’re currently running many microservices in Google Kubernetes Engine (GKE), where some of these microservices communicate with other microservices in the same data center, forming groups or graphs of microservices that achieve certain business logic as a whole:

Figure 1: Larger service graphs demand faster communications and easier API management
Each service graph formed from a group of these microservices can have a transitive communication between microservices, i.e. a microservice, Service X, might be sending requests to N services in the group, and in turn N services might be sending requests to M services, and so on. The requests going between these microservices, demonstrated in Figure 1, include RESTful payloads that are sent around using ‘HTTP/1.1’.
As the number of microservices in our infrastructure grows, so does the scalability and maintenance of the platform that provides communication ability to microservices. Specifically, when we started looking at migrating our mission critical microservices to gRPC, we were looking to get multi-language and platform support, scalability, persistent and reusable connections between client and server (using ‘HTTP/2’ and Linkerd), and bi-directional streaming by moving to gRPC.
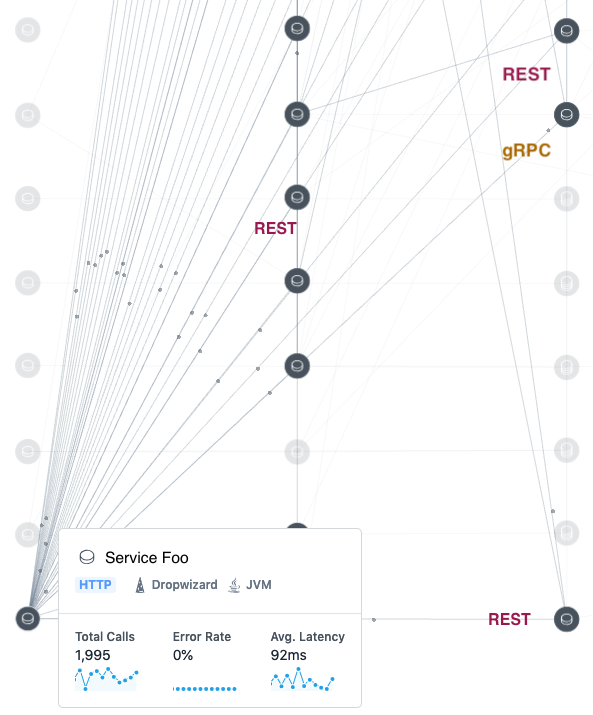
Figure 2: A group of services in the graph communicate in multiple data serialization formats
Legacy services with REST-only APIs are slowly moved to adopt and implement gRPC to improve our overall product’s performance. Figure 2, shows a group of services that are communicating with one another in REST and gRPC as the migration to gRPC happens for our services. Later in the post, we look at how services are updated to accept both serialization formats until all of their APIs are migrated to gRPC.
As we’ve added new microservices and languages to our infrastructure, gRPC offerings have become important to us, especially in terms of making growth easier both from scalability of the infrastructure and making microservice integration easier for our developers. gRPC documentation goes into more details on the importance of using gRPC on a per-case basis, and our recent gRPC focused meetup discussed more about some of the use cases and what the more important features are that can be used in similar infrastructures.
Why use gRPC?
In the microservice world at WePay, every microservice was using REST with JSON payload as a standard way of communicating with one another. REST has its advantages for service-to-service communication:
- JSON payloads are easy to understand.
- As a mature serialization format, there are lots of frameworks available for building services using REST.
- REST is a very popular standard and is language and platform agnostic.
As the number of microservices increase in the infrastructure, the service graph becomes more complex, and as a result, there are pain points and limitations in using REST for communications:
- For example, in Figure 1, When a client makes a call to service X, in turn, service X could make calls to other services to provide a response to the client.
- For every REST call between the services, a new connection is established and there is the overhead of SSL handshake. This would cause an increase in overall latency.
- The client has to be implemented for each service in every language required and also has to be updated whenever there is a change in the API definition.
- JSON payloads are simple messages that have relatively slower serialization and deserialization performance.
With these pain points in mind, gRPC seemed to be a good option for us to improve our microservices communications in our infrastructure.
In gRPC, a client application can directly call methods on a server application on a different machine as if it were a local object, making it easier to create distributed services.
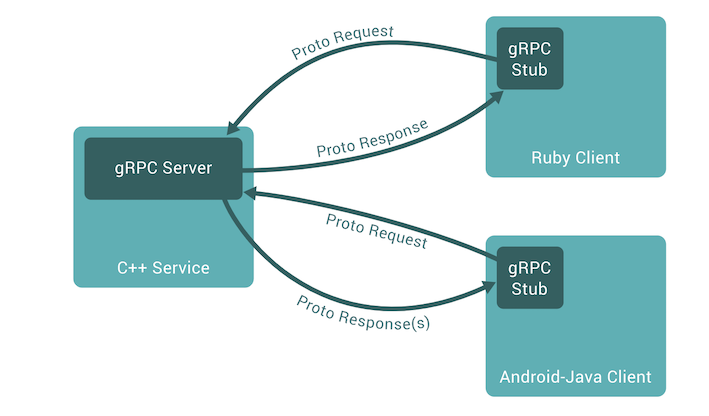
Figure 3: gRPC clients sending the proto request to gRPC service and receives the proto response (source)
gRPC has its own advantages:
- Similar to RPC protocols, gRPC is based on the idea of defining a service and its methods that can be called remotely with their parameters and return types.
- Building low latency and highly scalable microservice call graphs
- gRPC uses Protocol Buffers by default, which provide better performance when compared to JSON.
- Ability to auto-generate client stubs in several languages, which reduces the responsibility of building and maintaining client libraries.
Requests using Protobufs
Protobufs are text files that define the structure of the message and have a “.proto” extension. They are compact, strongly typed and support backward compatibility. They are used for defining service and the request and response data structure and types.
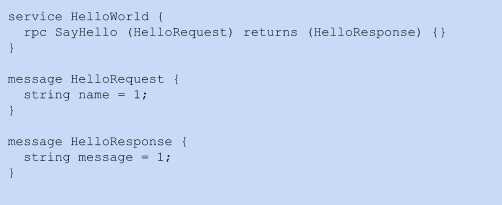
Code 1: HelloWorld gRPC service with a single RPC method "SayHello"
Protobufs as payload has better serialization/deserialization into binary format. This makes it faster than JSON. Also, clients can receive typed objects rather than free-formed JSON data.
Figure 4: JSON vs Protocol Buffers
Each language has its own protobuf compiler that converts these files into code. For example, if we are trying to get generated code in Java for service in Code 1, then the compiler generates:
- A base implementation which can be extended to implement RPC methods.
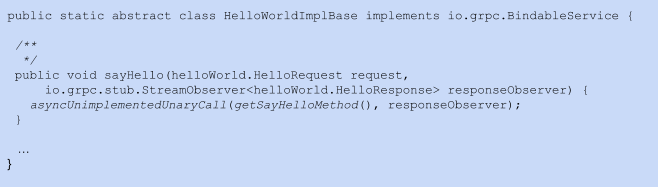
Code 2: HelloWorld implementation base class that was autogenerated in Java
- Stubs that can be instantiated by the clients to make calls to the server

Code 3: HelloWorld stub for Java clients
- Objects for the request/response messages which are exchanged between the server and client.

Code 4: Generate code in Java for protobuf messages
Connection Reuse
gRPC communication happens over HTTP/2. HTTP/2 enables more efficient use of network resources and reduces latency by using header field compression and allowing concurrent exchange in the same connection. In gRPC, the connection and exchange are referred to as a channel and a call. In this way, gRPC helps in reducing the latency of creating new connections for each request which is one of our limitations in using REST for a more complex service graph.
How to migrate from REST to gRPC?
Based on the benefits mentioned above, we decided to migrate our REST services to gRPC. There were many strategies we looked upon for the migration. One of the approaches was to build a gRPC application and use grpc-gateway to generate a reverse-proxy server which translates a RESTful JSON API into gRPC. This required adding custom options to gRPC definitions in protobufs, and add an additional container running this reverse-proxy server.
Some of the important requirements for migrating services to gRPC include:
- Requiring a minimal amount of rework.
- Not changing the current build & deployment pipeline.
- Enabling REST & gRPC as a first step and gradually migrating all communications to gRPC. This way, existing clients can continue to talk to servers via REST, until they are migrated.
- Complying to the same base platform for our gRPC as for REST microservices. For example, REST microservices inherit a few common default endpoints that help us monitoring these microservices. gRPC services should also support the same.
Based on these criteria, we decided to run the gRPC server as a thread in the application that uses the REST framework.
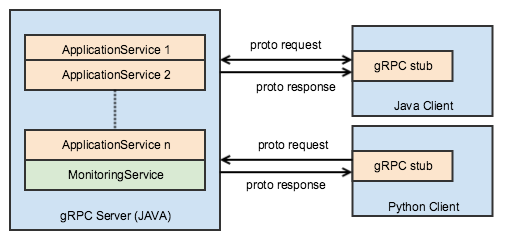
Figure 5: Structure of gRPC services and clients at WePay
As a result, we built a shared library that can be plugged into our microservices. This shared library includes a monitoring service that implements the RPC methods to check the health of the gRPC services. The shared library provides a “GrpcServerBuilder” that contains:
- Ability to add interceptors by default. The common interceptors would include can do exception handling, request/response tracing, authentication, etc.
- Adds the common monitoring service by default which provide rpc methods to check the health of service and its dependencies.
Developers use the GrpcServerBuilder provided by the shared library, and add the gRPC service implementations for the microservice and build the gRPC server.This will ensure a standard pattern for monitoring the health of all our microservices.
Communications using Service Mesh
As we mentioned in our earlier blog about using Linkerd as a service mesh proxy at WePay, Linkerd supports HTTP/2 and gRPC out of the box. But the setup to route gRPC calls to appropriate Kubernetes service was tricky. In service mesh, REST calls from the clients were redirected to the services running in Kubernetes by providing the service name in the path. For example, if we have a Kubernetes service named “foo” that runs a REST service, then using Linkerd, the client calls can be routed to service using the path as “foo/”.
gRPC uses HTTP/2 as transport. The request/response between gRPC service and client follows a specification. One of the main fields of the request is “path”. The path for the request is set to:
<package_name>.<grpc_service_name>/<method_name>
Linkerd can use either path or header as an identifier to route requests from clients to services. For gRPC, there were serveral challenges when choosing an identifier:
- In general, the Kubernetes service names need not be the same as the gRPC service names. For example, there can be a Kubernetes service named “greeter” that runs gRPC service named “GreeterService”
- An application running a gRPC server can run one or more gRPC service implementations. For example, the default gRPC monitoring service is added to our gRPC microservices along with the main gRPC service implementation(s) to make up a complete gRPC microservice at WePay.
These cases make it hard to use the path as an identifier. We solved it by forcing the clients to set a custom header “service” to the Kubernetes service name. And Linkerd is configured to use header “service” as an identifier for gRPC calls.
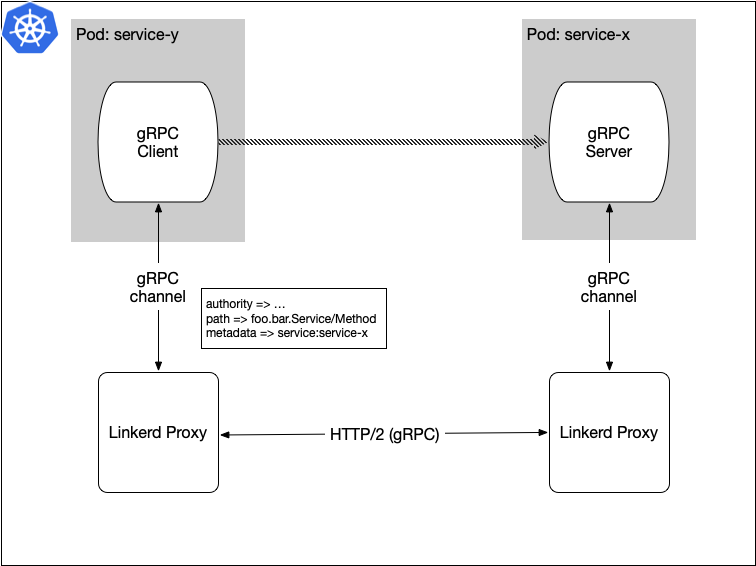
Figure 6: Demonstration of routing gRPC calls using the request header as an identifier.
In the common library we built for clients, we added an option to set the header as target Kubernetes service name. And Linkerd uses this header and identifier to route requests from the client to service.
CI/CD Lifecycle of gRPC services
A gRPC service has its own lifecycle:
- Write service and request and response definitions in the form of protobufs.
- Validate the protobuf files before using them to generate code for implementing clients.
- Implement the server and client(s).
There are some criteria to be considered when deciding the lifecycle of protocol buffers.
- Where to store the protobuf files?
- How to generate code and use it to implement servers and clients?
- If a proto file changes, how to identify that the client is updated to use the latest protobuf definitions?
This section describes how we were able to satisfy the following criteria and set up the lifecycle of gRPC services.

Figure 7: Lifecycle of gRPC at WePay.
Since we use a Service Oriented Architecture at WePay, we need to write and maintain protobuf files for many services. We decided to maintain a central git repository to store the protobuf files containing definitions for all the gRPC servers at WePay.
protos/
|-<service-x>/
|- **/*.proto
|-<service-y>/
|- **/*.proto
|-commons/
|- **/*.proto
These proto files are then validated using prototool in our Continuous Integration (CI) servers, and then we create release tags in the git repository from the master for the changes.
To implement gRPC servers/clients, we need to generate code from the protobufs. We do that by fetching protobufs using the release tags to the application repository and use the protoc compiler to generate code in the required language and use them to implement the server/client.
Currently, we generate REST API documentation for microservices using tools like RAML, Swagger, etc. Our common microservice build process generates API documentation. Similarly, we have set up a build process for microservices which are also configured to generate gRPC documentation using protoc-gen-doc plugin.
Challenges of moving to gRPC
gRPC has many advantages, but not all the microservices that are in REST can be migrated to gRPC. For example, migrating external services might require rework for the clients using the REST API.
There were a few gRPC development challenges for us when migrating our existing REST microservices to gRPC, and below are the most important ones.
Browser Support
Until recently, gRPC had no support for browsers. Currently, one of the popular ways to let browser client access gRPC service is using grpc-web. The browser clients connect to gRPC service using a special gateway proxy. We did not use grpc-web for external services because the GA version was not available when we made this decision. We also have many JSON schemas for our front end, and converting all of that over to protos is non-trivial. This change would also require updating all of our SDKs.
Protobuf restrictions
Some of our API needs to identify the difference between following in a request/response data:
- A field not existing
- A field existing with a null value
- A field existing with a non-null value.
Using proto3, we cannot easily identify these differences. Although, We can use google wrappers to identify if the field is set or not set. The potential use cases where we want to identify the null values are in update type of requests, where the servers receive request to set some fields to null. i.e. If there is an existing message in the backend and if we need to set null to one of the fields (also otherwise meant in protobuf world, as to clear the field). We can use Field masks in these types of scenarios.
gRPC and HTTP framework
Currently, microservices that are written using REST frameworks assume request handlers are part of an HTTP stack and has the ability to execute middleware such as authentication checks, request/response logging, metrics tracking, and so on so forth.
There aren’t any existing gRPC frameworks that have feature parity with the HTTP frameworks that we use. But, gRPC provides “Interceptors” to enable these middlewares. We build interceptors for each feature we want for our gRPC servers, and package them as a common library to be used by all of these microservices.
Protobuf versions
Protocol buffers language has two syntax versions: Proto2 and Proto3. gRPC supports both the versions. The Proto2 and Proto3 are similar but have few differences.
| Feature | Proto2 | Proto3 |
|---|---|---|
| Fields can be set to NULL | No | No |
| Required message fields | Yes | No |
| Ability to set custom default values for a field | Yes | Removal of default values. Primitive fields set to a default value are not serialized |
| JSON Encoding | Uses Binary protobuf encoding | Addition of JSON Encoding |
| UTF-8 checking | Not Strict | Strictly enforced |
| Ability to identify if a missing field was not included, or was assigned the default value. | Yes | No. In Proto3, When we use primitive fields, we cannot differentiate a default value being set and field not set. We can fix this by using wrappers (well-known prototypes) instead of primitives. |
Table 1: Comparison between proto2 and proto3
It is hard to make a decision on which version of protocol buffers to use. As mentioned above in the comparison table (Table 1), there are some backward incompatible changes from proto2 to proto3. So, it is better not to update if the gRPC services are built already with proto2. If we would like to use features like setting custom default values, identifying a missing field, required message fields, then we can use proto2. We can choose proto3 if we want to utilize new features and use alternatives for the features that are available only in proto2.
Conclusion
In conclusion, based on the number of microservices, performance, and maintainability requirements, we decided to build our new microservices using gRPC, and to migrate all of our existing microservices to gRPC, where applicable.
This gives us:
- Strongly typed service and request/response definitions that are written once and generated code in multiple languages.
- Better performance with HTTP/2 where connections are reused.
- One less thing to maintain in terms of building client libraries.
- Support of streaming calls for high load of data.
Now that we are able to improve our service-to-service communication throughout our infrastructure, we need to keep our infrastructure and platforms that these services are running on up-to-date and continuously improving.
In the next post, we’re going to look at how we manage the lifecycle of the infrastructure to achieve continuous infrastructure improvement with zero downtime, and without affecting the overall health and performance of our production services.