
An Offline to Online Data Pipeline at WePay
Background
Historically, our approach to fraud detection primarily relied upon the data available in production. This meant that all attributes required for making a decision on whether each payment transaction is legitimate or fraudulent relied solely upon the availability of supporting data in production. Another approach to fraud detection was to run various queries on BigQuery, which is our data warehouse, to identify specific patterns (or signals) and send the results to risk analysts who were interested in the output. The analysts would manually go through the results and then possibly recommend if these data points could be applied in production to live payment traffic to fight fraud. This approach had its shortcomings because it did not really stop payments from going through in case of fraud as there was a significant delay in propagating and applying the newly found data points to the payment transactions in production. Also, it was error prone and un-maintainable as the entire process of identifying the new data points from the queries to their application in production was very manual.
Our Goal
In the new system, we attempt to bridge the gap between the offline datasets and online (or production) fraud detection mechanisms in an automated way. Using this approach, data scientists and risk analysts can run very complex and resource intensive queries on large offline datasets and the system provides the necessary infrastructure and functionalities to immediately surface these results or interesting patterns to production that can be used and acted upon for fraud detection.
Oftentimes, there are very interesting patterns that could be found in offline or historical datasets. However, the task of actually making use of these insights and applying them to classify production transactions as fraudulent or not can be a very manual and cumbersome effort. Thus, we envisioned a data pipeline that allows users to perform very complex computations and queries and surface the results of such computations to production. Hence, this pipeline helps to leverage the patterns found in offline data to be applied and acted upon in production.
Approach
The overall ecosystem of this end-to-end pipeline can be divided into two broad sub-systems - an Airflow component and a microservice component. The architecture is as shown below.
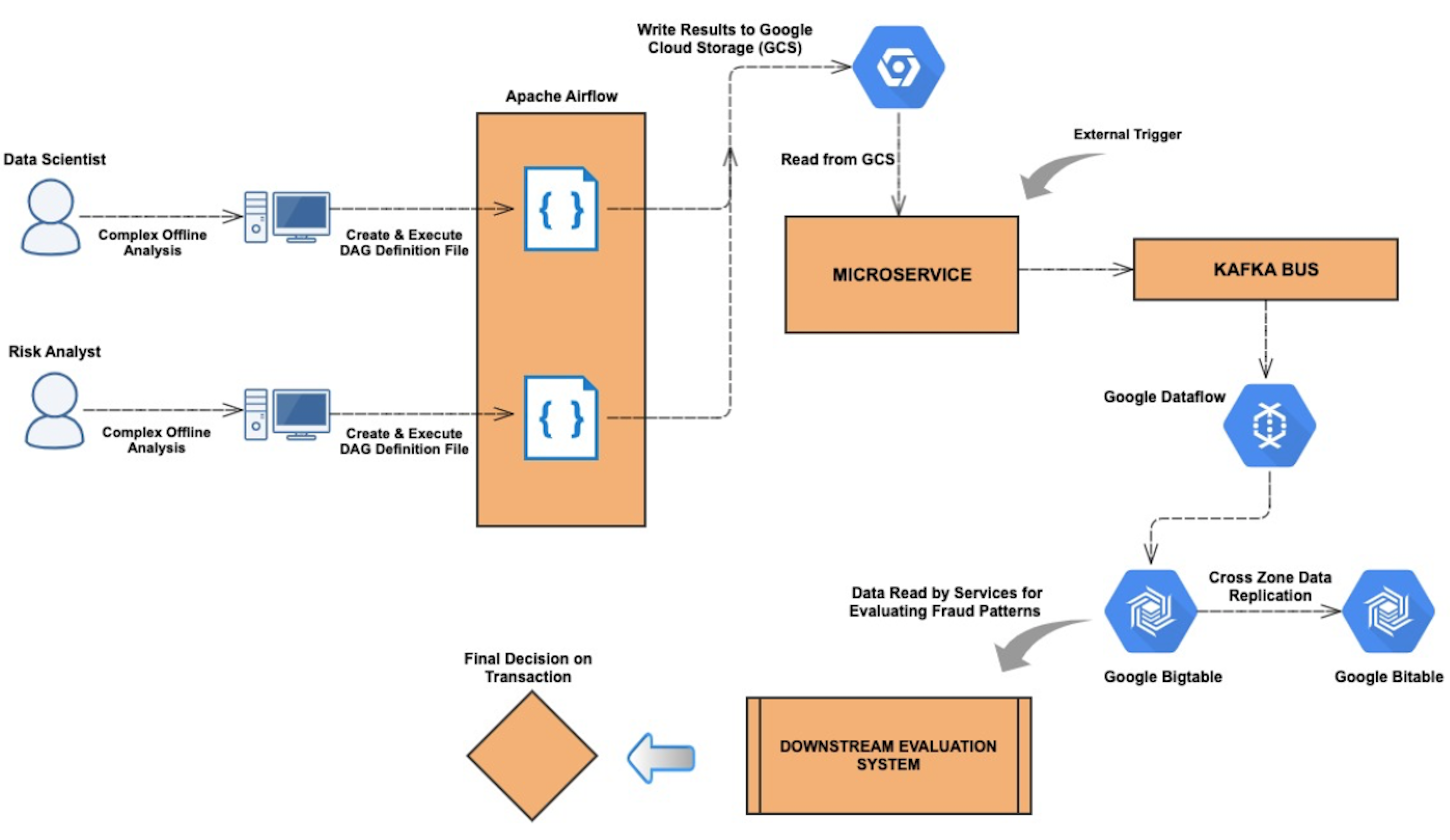
As it can be seen from the architecture above, any offline computations or complex analysis performed by users can be seamlessly integrated and propagated in our production environment to fight fraud. Specific rules can be created that can leverage these newly found data points and act on them to detect fraudulent payments. The entire setup involves using state-of-the-art data processing solutions such as Google Dataflow and persistence solutions such as Google Bigtable which is a highly scalable NoSQL database for processing large scale workloads. We also use Google Bigtable’s built in cross-zone data replication mechanisms to replicate our data to make it highly available across multiple zones.
Airflow
Users of this pipeline start off with creating two input files - a SQL query file that contains the query to be executed on BigQuery and a JSON specification file that contains various metadata information. An example of these files is shown below.
SQL QUERY
SELECT
merchant_id AS id,
risk_rating AS risk_rating
FROM
[DATASET_ID:TABLE_NAME]
JSON SPECIFICATION
{
"version": "1",
"schedule_interval": "* 20 * * *",
"start_date": "2018-02-15",
"post_actions": {
"email": ["test@test.com"]
},
"result": {
"entity": "Merchant",
"columns": {
"1": {
"name": "id",
"type": "integer"
},
"2": {
"name": "risk_rating",
"type": "float"
}
}
}
}
1. The columns in the query are the patterns (also known as signals) that we want to propagate to production so that their values can be used to make risk decisions.
2. The JSON specification file captures the metadata for the columns in the query such as the datatype of the columns. There are some additional fields in the JSON file that are used in the auto-generated DAG definition file. In the above example, we are trying to query for merchant ids and their pre-computed risk ratings from historical data from a table on our data warehouse. Once the two input files are ready, users execute a custom script that reads these files and auto generates an Airflow DAG definition file. The DAG is responsible for the following actions:
2. The JSON specification file captures the metadata for the columns in the query such as the datatype of the columns. There are some additional fields in the JSON file that are used in the auto-generated DAG definition file. In the above example, we are trying to query for merchant ids and their pre-computed risk ratings from historical data from a table on our data warehouse. Once the two input files are ready, users execute a custom script that reads these files and auto generates an Airflow DAG definition file. The DAG is responsible for the following actions:

As a result, at the end of the DAG execution, we have the output of our query execution available on a Google Cloud Storage bucket along with the specification file.
Microservice
The system includes a microservice whose endpoint is triggered by a separate airflow DAG at regular intervals. This endpoint is responsible for accessing the bucket on Google Cloud Storage, reading the CSV and JSON files, extracting the information and publishing the contents to Kafka. Now, in the downstream, we have streaming Google Dataflow jobs that are continuously listening for events on the kafka topic and are responsible for reading the data from Kafka, convert the messages to Google Bigtable mutations and finally write the results to Bigtable. Bigtable serves as our signal storage.
Results
Ever since we operationalized this system, our data scientists and risk analysts have been able to create and propagate hundreds and hundreds of patterns or signals that have proved highly useful in detecting fraudulent patterns in payment transactions. As the whole system is automated once the user generates the DAG definition file, the turn-around time to apply one’s useful and complex analysis to live payments on production is very quick thereby making our fraud detection and prevention systems more robust to changing fraud patterns.
Final Thoughts
This pattern is powerful because data scientists and analysts typically have access to a large amount of offline data. These data points could be from multiple different sources. Be it historical data, open source data and so on. The pipeline provides a generic platform for users to identify and analyze patterns in large datasets to get meaningful and actionable insights that help in identifying and detecting the fraudulent behavior of payment transactions.
By the way, if you are interested in doing this kind of work, WePay is [hiring!]