

Autoscaling CI/CD on Google Cloud: Part 2
In the last post we drew a picture of what was detailed as a distributed autoscaling system using Google Cloud Platform’s Compute Engine resources, specifically using Google Compute Managed Instance Groups. A few limitations and challenges with the distributed approach lead us to further research and design for autoscaling using a central autoscaler, and in this post we talk about how we used the TeamCity server to centrally autoscale our CI/CD system and the positive effect this change has had on the overall system’s cost and developers’ productivity.
The second approach to designing auto-scalable agent pools for our CI/CD system was making use of the TeamCity server as an autoscaler or an autoscaling orchestrator. Just like the distributed cloud-native approach, the configuration and bootstrapping responsibility is encapsulated and isolated from the CI/CD system and is delegated to the cloud resources, i.e. Google Compute Instances and Templates.
Centralized autoscaling
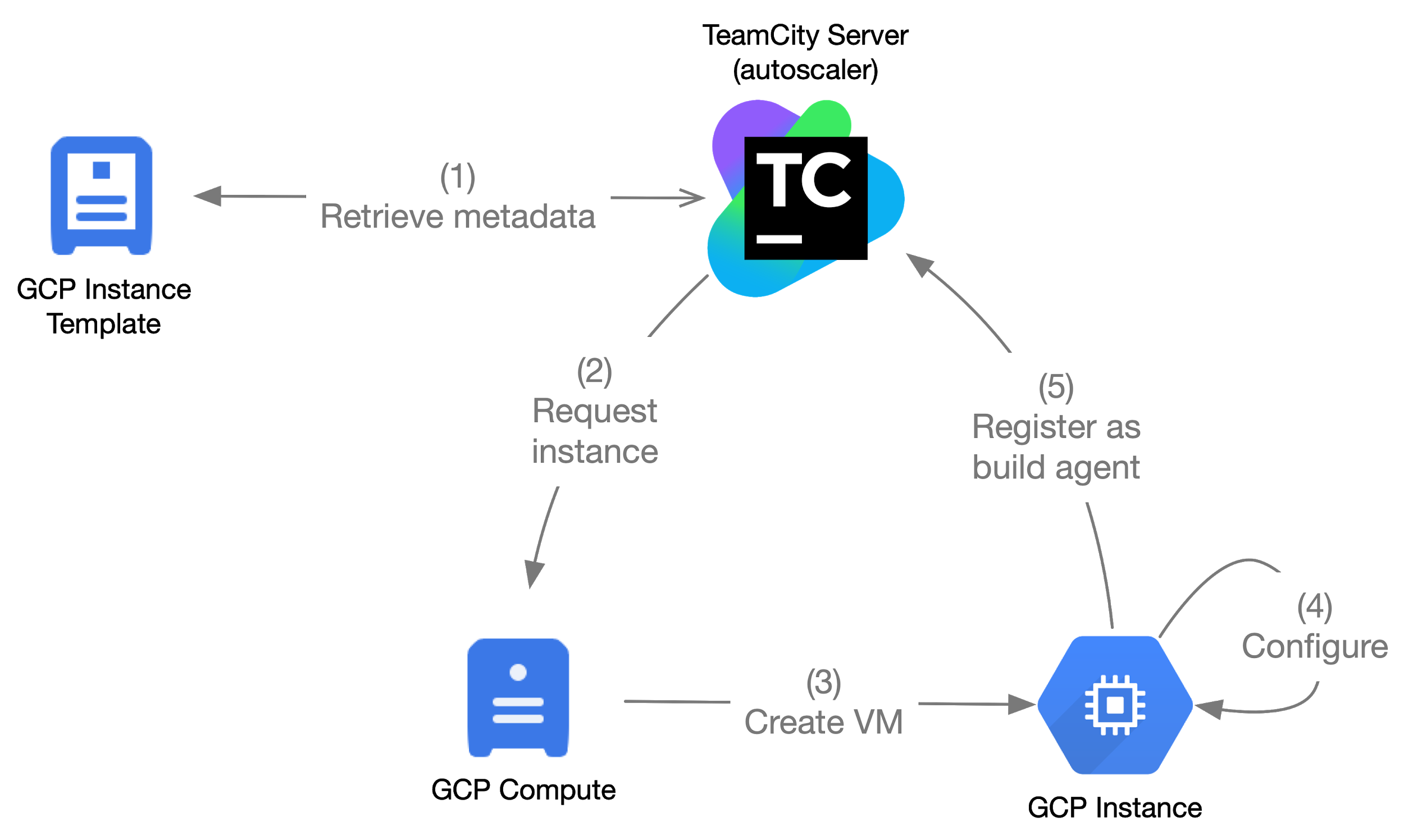
Figure 1: A central autoscaler, and delegation of responsibility to their corresponding components
At the center of operations in Figure 1, TeamCity server acts as an autoscaler that orchestrates creation of Google Compute Instances. Once an instance is created, the startup logic of an instance pulls the appropriate configuration for the instance, bootstraps the agent, and registers itself with the server as demonstrated in the previous post in Figure 3. This permits the system to react a lot faster to autoscaling events due to the autoscaler decisions happening within the TeamCity server’s (plugin) code.
In addition to the benefits mentioned above, there are some other appealing advantages to this approach over Cloud Instance Group autoscaling:
- All cloud configurations are done in one place in the Agent Cloud Profiles, with the server acting as a control plane, showing the state of each agent pool at a given time. This makes the setup a bit more cloud-agnostic.
- Makes use of Google Instance Template’s metadata for bootstrapping from code and detaching the configuration responsibility from the CI/CD system components.
- An established design using TeamCity plugins that makes use of an event-driven approach for making faster decisions about its autoscaling events.
- The ability to extend an already open sourced solution with the corresponding toolset that the community can also benefit from.
On the other hand, there are certain things that we may miss out on:
- Impacted visibility due to an API-only integration between TeamCity and the cloud (GCP), where only the TeamCity server is aware of the autoscaling events and orchestrating the changes to the cloud resources.
- A solution that’s tied to a specific service, TeamCity, and any other system needing to implement such scalability would have to implement a similar orchestration in their own ecosystem.
Overall, this was a better solution for our use case given the better performance and the mentioned toolsets availability for extension. In the future, and as the Kubernetes toolset for TeamCity becomes more mature, we plan to migrate what has been built and setup here to the Kubernetes ecosystem to make configuring and maintaining this infrastructure easier. During the design of this system, we felt that the Kubernetes and containerized Build Agent support is not as mature as the Virtual Machines, so we stayed within GCE for building out our autoscaling solution.
Life cycling build agents
For achieving an automated build agent life cycle, we broke down the requirements for the automation into smaller building blocks that were built independently. Each build agent starts with a Google Compute Image, built into immutable and versioned artifacts that are then configured in a bootstrapping stage for serving jobs in the build queue, (demonstrated in Figure 3 of the previous post). These build agents are then autoscaled using the method described above, Figure 1.
Provisioning
Provisioning is an essential stage to guaranteeing fully automated autoscaling. This stage is responsible for separating the creation of an immutable image from the following downstream stages of autoscaling, bootstrapping and build agent configuration.
This encapsulation ensures that the build pipeline doesn’t affect the deployment pipeline, if any issues arise when building the immutable images, and also yields a build pipeline that can run independent of the deployment pipeline, reducing the deployment time at the same time.
We’ve used Hashicorp Packer in the build pipeline to ensure an easy configuration for multi-cloud images, where necessary. Using this provisioning stage, we can also re-use the resulting immutable images for more predictable rollouts, and reproducing issues that may be uncovered at deployment time, given that in an autoscaling environment build agents are ephemeral.
Bootstrapping
An immutable image needs to undergo certain steps to be transformed into a registered *build agent that serves the build queue maintained by TeamCity server. In our case, these steps are defined and configured to be executed during a GCP Instance startup, *Figure 1 step (4), which involves:
- Build agent process configuration: The agent relies on specific configurations that are pulled into the instance at startup to communicate and register with the server.
- Build agent registration and authorization: Using its local configs, the build agent registers itself with the server. Once the agent is registered, the server authenticates the agent to the proper agent pool. This is the stage where a purchased license (maintained by the server) is allocated to the new build agent, and then follows the server’s instructions for full registration. The build agent manager plugin ensures that scaled down build agents release their license and are cleaned up from their agent pool after a full shutdown.
- Agent pool configuration: At this stage the agent is ready to execute builds. With our autoscaler configuration tied to each agent pool, we ensure that the agent brought up is assigned to the correct pool, and that each pool acquires the right number of agent licenses based on usage (as described in Data 1 and 2 in the previous post).
- Addition of network tags: The agent is now active, and its instance is tagged with custom defined bootstrapping tags, communicating the close of the autoscaling loop.
Rollouts and debugging
Our CI/CD system required multiple agent pools with different configurations for their agents. We had to ensure that these configurations were kept separate from the autoscaling functionality. We use Instance Templates for this purpose, which are able to bake these configurations into an Google Compute Instance using the supported startup scripts and custom metadata attributes, thereby eliminating the need for any manual intervention. This way, we also have the capability to perform canary or “shadow” testing of these templates against a staging environment to catch potential issues. New rollouts are also made easier since we only need to modify entities in the template to release a newer version of the instances that are used in the pools.
Runtime operations and Day 2+
Live metrics
Resource and service level metrics have helped us tremendously in understanding our CI/CD system’s performance and usage before and after enabling the autoscaling configurations. These metrics have empowered us to tweak each agent pools’ configuration in a way that makes most sense for each type of agent pool as opposed to generalizing the final configurations.
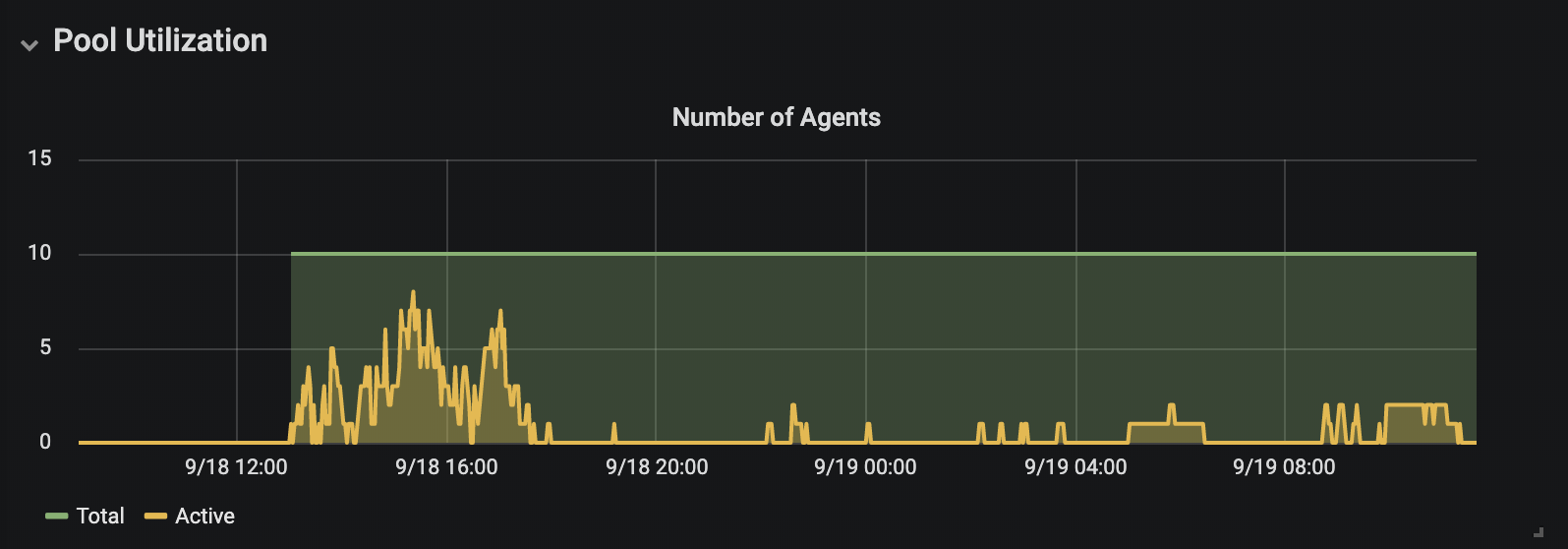
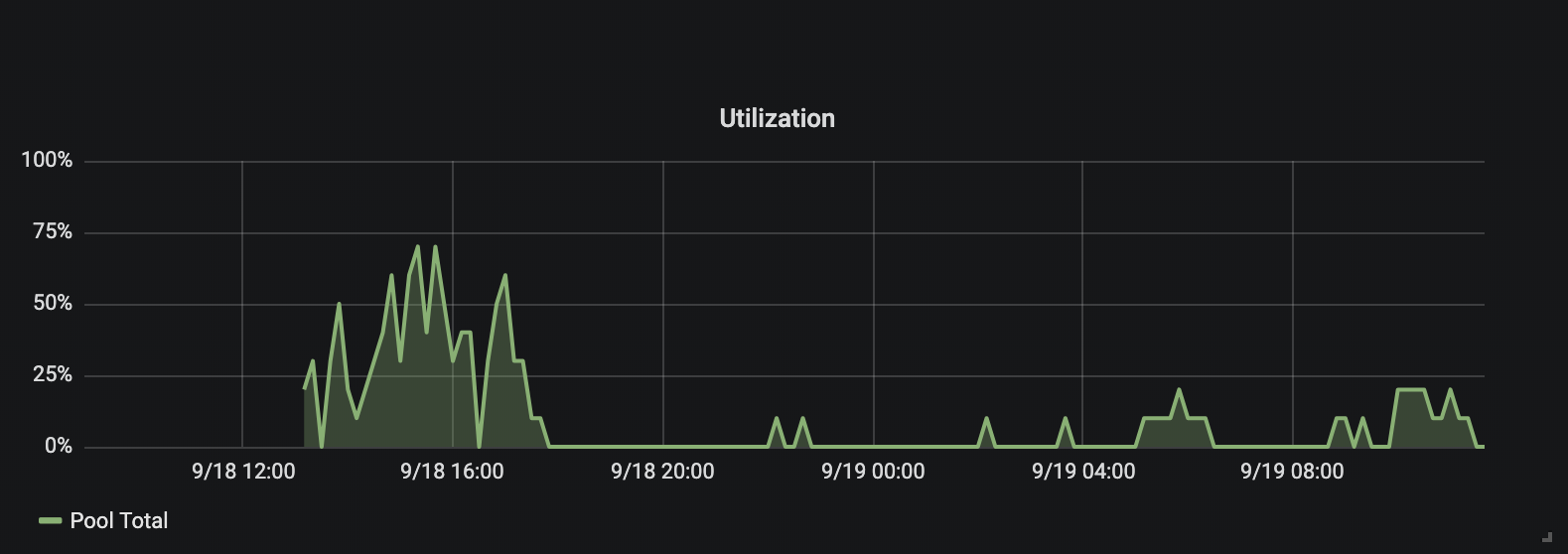
Data 1: Overall agent pool utilization prior to autoscaling
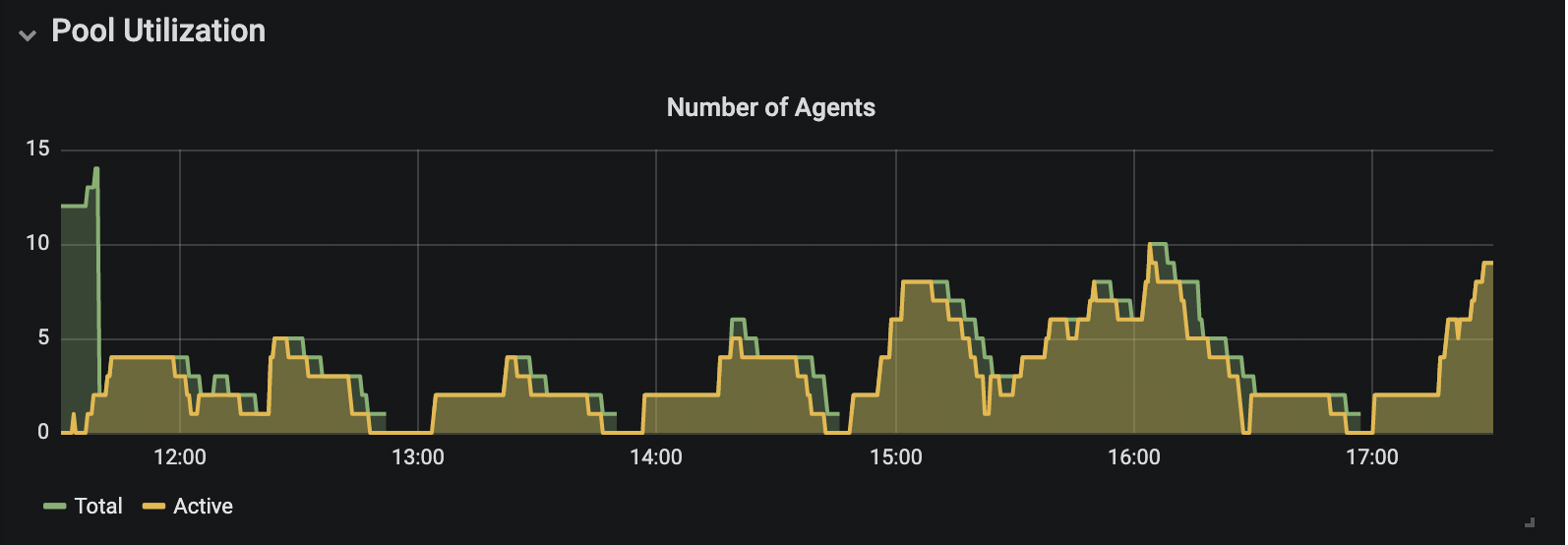
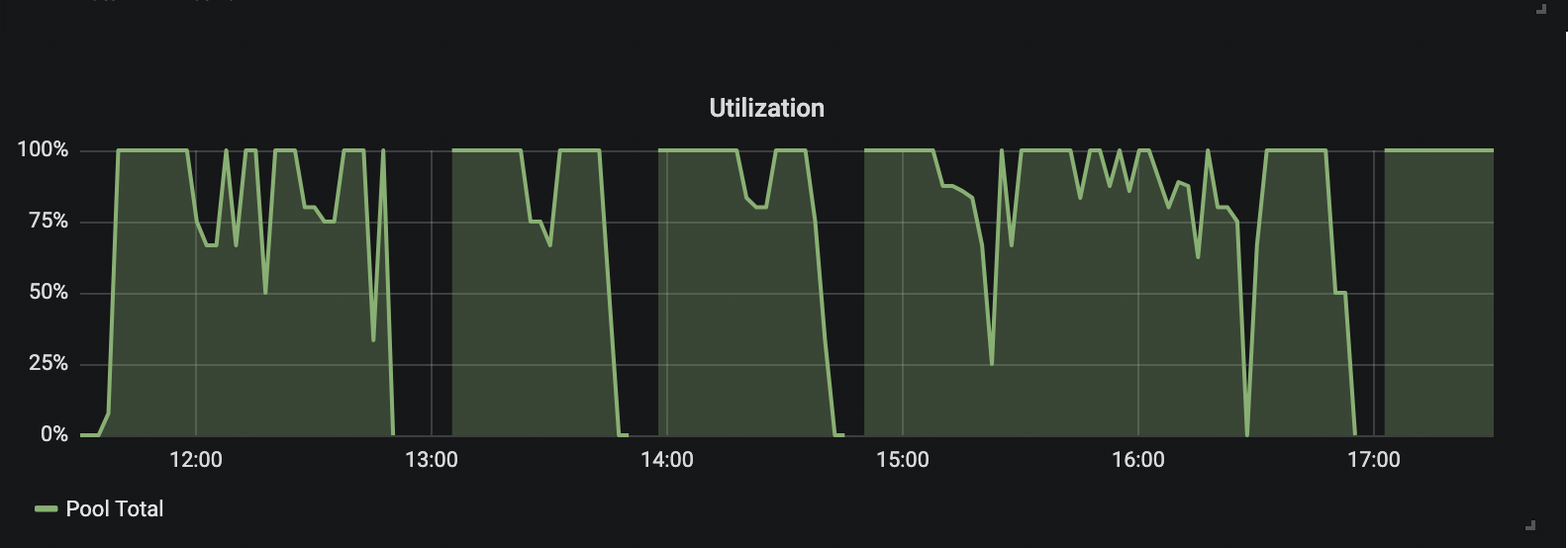
Data 2: Overall agent pool utilization configured to be autoscaled
Graphs in Data 1 and Data 2 are built to show the overall utilization of the same agent pool before and after enabling the autoscaling configurations. Data 2 mainly reveals how autoscaling has permitted us to maximize the resource usage in each agent pool based on the demand from the build queue.
These graphs uncover other types of data like startup time performance and scale down wait time, configurable per agent pool. The startup time can be calculated by looking at the increase in the total number build agents in the pool, and the scale down wait time is visible in the green shade on the fall of the graph in the Number of Agents graph in Data 2. Machine level resource usage (not graphed here) can also be used to pick the right type of machine types.
These are the types of data that we were able to use to measure the right autoscaling configuration values based on the needs for each agent pools.
Alerting
With an autonomous and centralized autoscaling solution in place, it is essential to configure alerting systems that notify us about potential issues in the system. Specifically, we need to be alerted for any indicators that the autoscaling is not working as expected.
The TeamCity server bases its autoscaling decisions on the size of the build queue. An increase in build queue size is met with a scale-up event while a decrease in the queue size is reciprocated with a corresponding scale-down event.
Any issues with the system will prevent the agent pools from being autoscaled, resulting in an ever growing build queue. Such undesired build queue size increase may arise from any of the following:
- Configuration: Agent pools are configured to operate with a ceiling limit on the number of agents at any time. This value is based on the maximum load this pool has seen historically and the available purchased agent licenses. Unexpected increase in the load can saturate the agent pool until the jobs are completed and at this time, no newer agents will be brought up for newer jobs.
- Infrastructure: There could be cases where there are unavailable agents to the cloud instance failures, agent bootstrapping issues, etc.
This means that we can be alerted about fundamental autoscaling issues by monitoring the build queue size. This serves as an early indicator of the health of the autoscaling system.
At WePay, we have incorporated Sensu, an infrastructure level product with monitoring, telemetry and alerting solutions. In addition to the basic health checks on the Teamcity ecosystem configured with Sensu, we added another check to monitor the size of the build queue and send alerts if the size exceeds a specific value over a period of time, Figure 2.
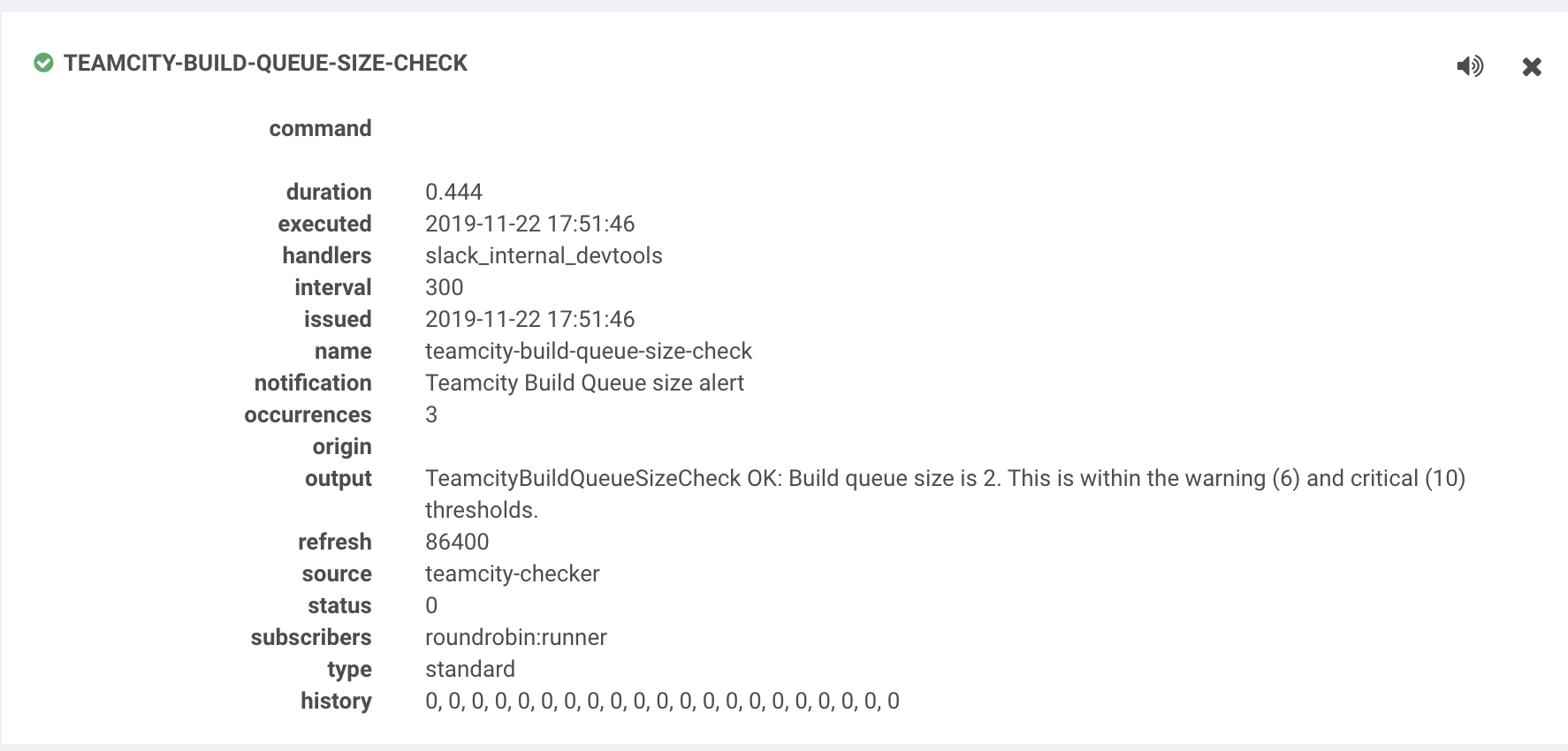
Figure 2: Build Queue size check details in Sensu
The check is configured to send an alert to a Slack channel if the build queue size exceeds 10 jobs over a span of 5 minutes. This check invokes a TeamCity RESTful API that returns the build queue size and derives a custom status code based on the warning and critical levels supplied as input parameters. The Slack alert is defined to only send alerts on critical events.
On the other hand, the autoscaling configuration limits the maximum number of build agents that can be created at a given time. So there might be a scenario where a high load on the build queue for longer than 5 minutes may trigger the mentioned alert. We use these alerts to recalculate the maximum number of build agents configured using the average total workload over the week for a given agent pool. If the average shows a higher maximum than configured, we can reconfigure the autoscaler to allow for more build agents for the given agent pool.
Workload and utilization
The autoscaling system that we’ve described above, contributes to what we refer to as a system that provides a best-effort availability.
This is based on observing the following:
- All build agents are scaled down to zero at quiet hours, which means no cold instances to convert to build agents for agent pools, or any idle build agents to re-enable or re-activate for immediate execution of jobs from the build queue.
- Each agent pool is configured to build agents with resource configurations matching the maximum resources needed for the builds with most complexity in an agent pool, translating to a performance-over-cost approach for our CI/CD system.
- Configuring new agent pools or rolling out newer versions of build agents is a one-time manual step that’s used by the autoscaler for the life of the given configuration.
- We’re working with VM instances (vs. containers) so the autoscaling operations are limited by the performance of GCP Instances, i.e. startup time is derived from time spent in kernel + init + userspace.
- Developer productivity with the CI/CD system can be maximized by the maximum number of build agents configured for the busiest agent pools.
Using this concept, we work on improving different parts of the system observed above as our use cases and infrastructure evolve.
Thoughts and future
Throughout this project we learned a lot about the different implementations of autoscaling in the cloud, and using our simulated testing environment learned about the limitations of each style, and why centralized autoscaling works best with a master/worker CI/CD system.
Using the centralized autoscaling, while increasing our CI/CD’s build queue throughput by up to 9%, we benefited from a few things:
- Elimination of the cost for running idle cloud resources, when there are no jobs to be executed by any of the agent pools.
- An automated way of configuring and bootstrapping build agents on new rollouts and autoscaling events.
- A simple way of configuring autoscaling for our CI/CD system based on workload trends and resource usage.
- Elimination of long waiting time for the jobs added to the build queue.
From here, we look forward to making more improvements to share with the community such as:
- Automating the way the autoscaling is configured to limit the minimum and maximum number of build agents in an agent pool.
- Better visibility into how the centralized autoscaling behaves at a given time.
- and, migration of the build agents to a framework, such as Kubernetes, with less overhead.