

Autoscaling CI/CD on Google Cloud: Part 1
At WePay we make heavy use of our Continuous Integration/Continuous Delivery (CI/CD) system to provide specialized and automated pipelines to all of our internal development teams, making it easier for the teams to build, test, verify, and ship their software faster, with more visibility, and easier integration with software from other internal teams. As the number of users for the CI/CD system grows, so does the load on the system and the need for adopting to higher workload in the system, a side of effect of larger number of builds passing through the system.
The Platform Infrastructure team at WePay is responsible for the self-hosted version of the JetBrains’ TeamCity system, and ensuring a healthy, reliable, and scalable CI/CD system as a whole. The TeamCity system runs in a master/worker model where a server, acting as a control plane, manages build configurations, build triggers, and traffic across N build agents and M agent pools, as shown in Figure 1.
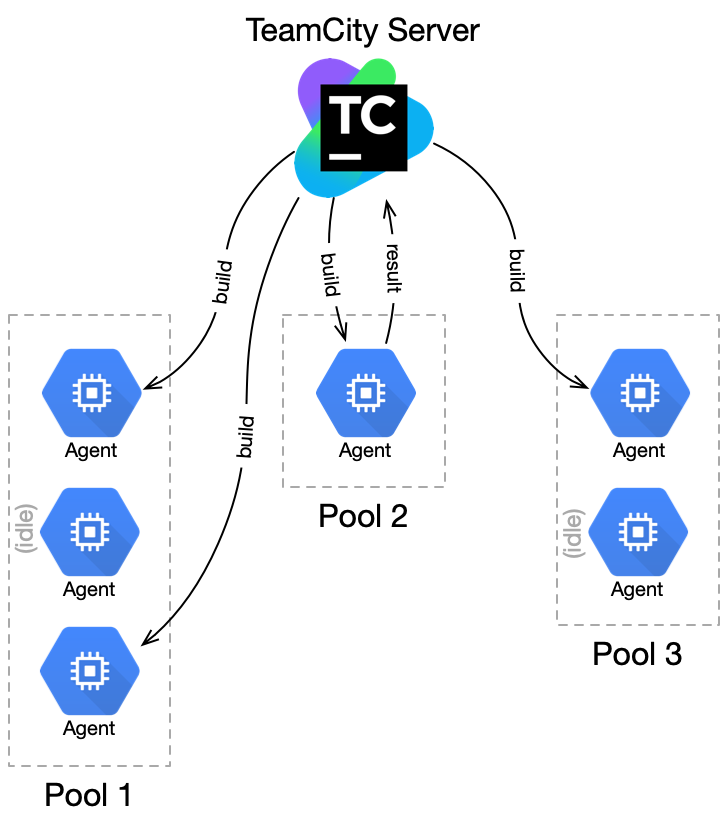
Figure 1: TeamCity server manages builds running on agents in different agent pools, and agents report back results to the server (Agents — with no builds to run — stay idle until they’re assigned to run a build)
Traditionally, each agent pool is a collection of build agents that are designed to serve special build or pipeline types, which may be separated based on resource type, execution frequency, running time, or development teams. In the cloud, e.g. Google Cloud Platform, these pools are maintained by a VM Instance Group, for ease of maintenance, which are created from a VM Instance Template that contains all the necessary metadata for automatically bootstrapping and configuring the corresponding runtime environment.
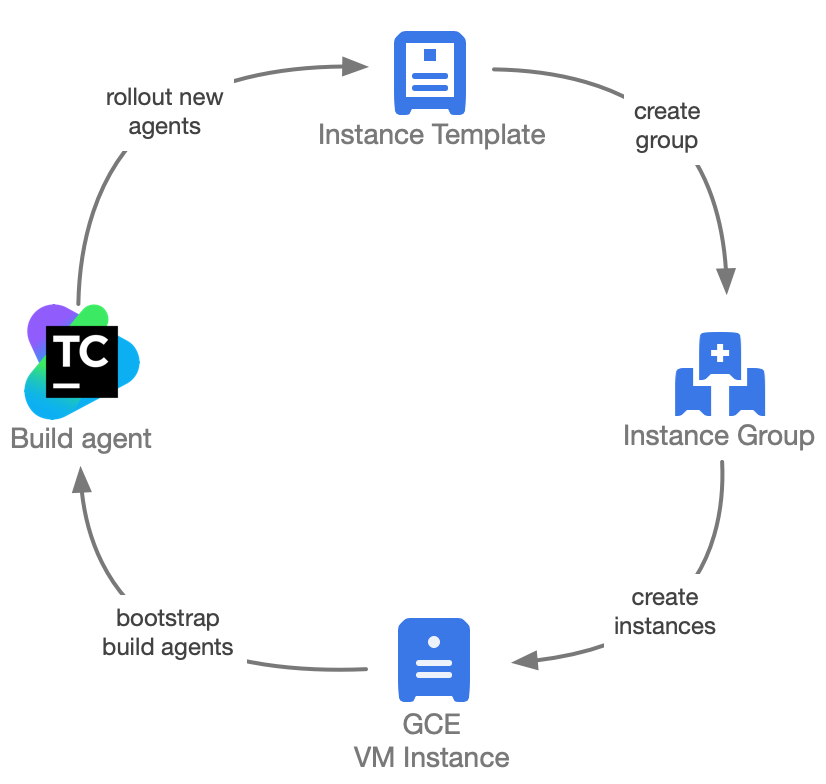
Figure 2: Build agents are GCE VM instances that are tied to an instance group configuration that is created from an instance template configuration
VM instances created by an instance group are bootstrapped and promoted to a build agent using a configuration manager like Ansible. Once a build agent is ready to serve builds, it registers itself with the server to start running builds in the build queue (Figure 2).
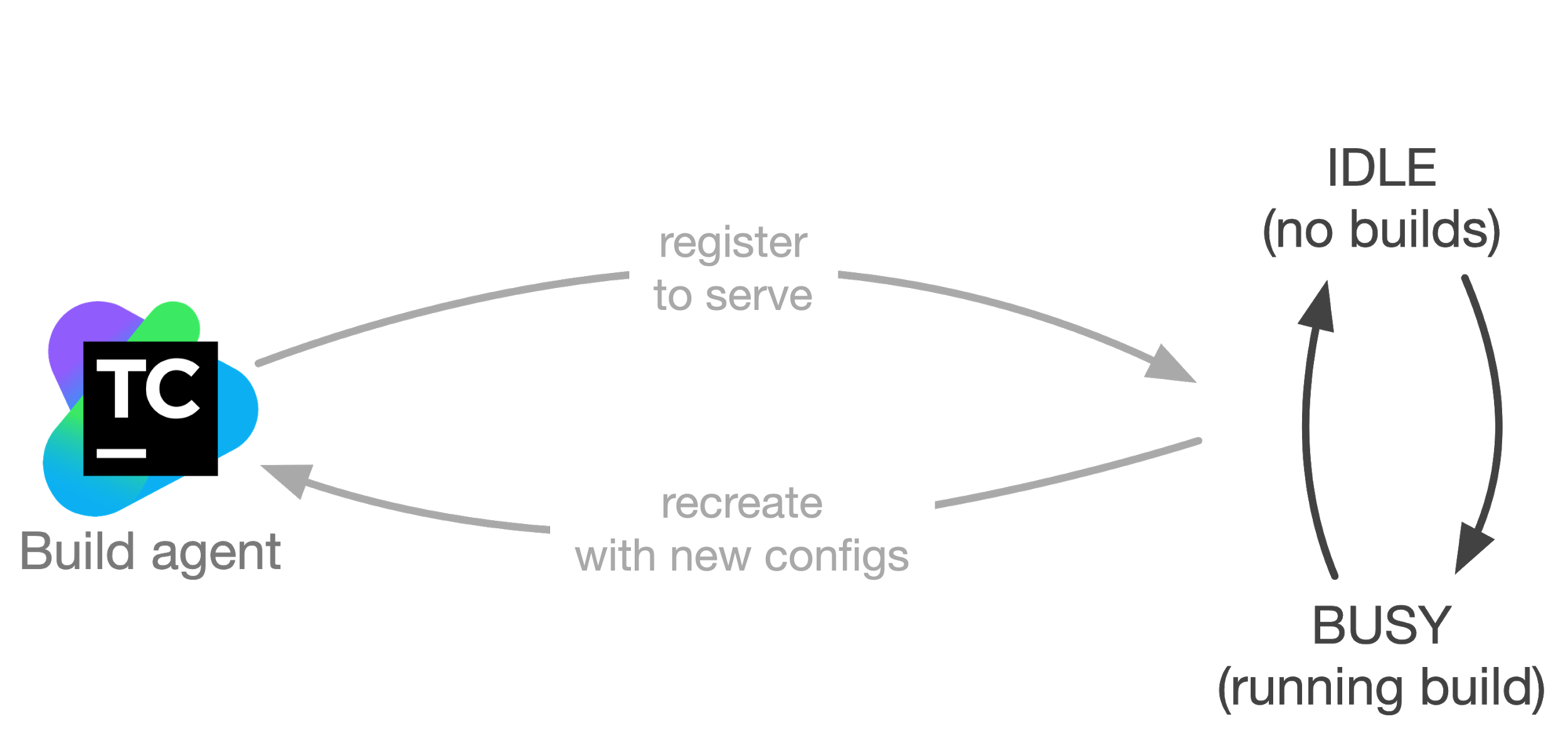
Figure 3: An agent in an agent pool serves builds in the build queue until it’s replaced by a newer version of the build agent configuration
Using this pattern, a build agent’s life cycle is summarized in Figure 3; A build agent serves builds that are assigned to it by the server, staying idle while there are no builds to run, and once there are application or configuration updates ready for the agents and their respective agent pool, the process described in Figure 2 is used to rollout the changes.
As the number of users of our CI/CD system increased, so did the need to define different sets of agent pools that catered to specific build types, with certain build types being used more than others. For example, there might be more builds for a development/staging pipeline than a production pipeline, or there might be more test jobs than build and deployment jobs in a CI/CD system.
Having idle or standby build agents helps with faster runtimes, but it also has cost and scalability implications. After analyzing the usage of the agent pools dedicated to specific build types over a period of time, we observed that on average an agent pool is busy doing work about 20-28% of the time in a given day, and some hours are busier than others in the day matching closely to popular business hours. In other words, running agent pools with a constant number of build agents allows for build agents to be idle somewhere between 72-80% of the time on some days.
This scenario required a more efficient and scalable solution for our CI/CD system. We also recognized the potential for improving the life cycle of the build agents built with the process defined in Figure 2, reducing the amount of human interaction which would allow us to work toward an automatically scalable solution with an improved maintainability of the overall system.
In this post, we’ll take a look at some of the case studies we leveraged for upgrading our CI/CD system to automatically scale based on a total workload over each agent pool, and as a first part to these post series, we will take a look at a distributed autoscaling solution on Google Cloud Platform. In a second post as a follow up to this one, we’ll take a look at a centralized approach and the improvements that were done to the life cycle of the build agents.
A total workload
As mentioned earlier, in our CI/CD implementation, builds are assigned to dedicated agent pools based on certain needs or restrictions. To better understand the scalability needs of each of these pools, the analysis needs to be broken down into metrics that would look at the automatic scaling of each pool, or simply a total workload metric value at a given time per agent pool.
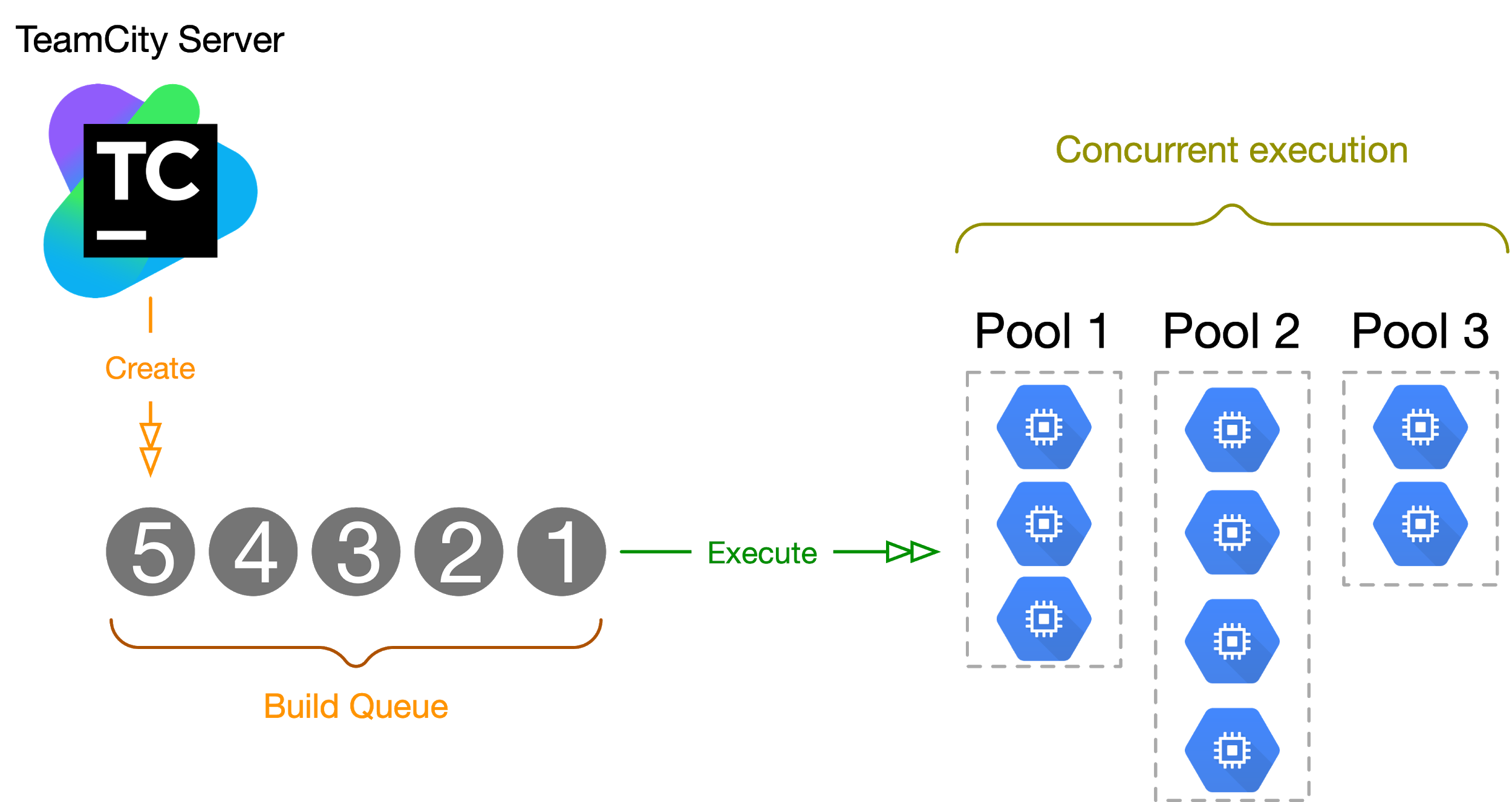
Figure 4: Jobs in the Build Queue are processed by the agents in their corresponding agent pool
This total workload value at any given time is derived from the flow that each build goes through; from the time of being added to the build queue until the complete execution on a build agent, as visualized in Figure 4. So by definition, the total workload of an agent pool can be defined as:
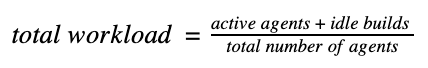
Function 1: Utilization for a given agent pool at time T
where, active agents are build agents that are actively executing a build, and idle builds have no outstanding parent build from their build chain in the queue or executing, and are simply waiting for an available agent for execution. Total number of agents is the sum number of agents that are busy and idle in the given agent pool. Using the total workload value an agent pool can be scaled up or down at a given time.
Workload trends
As briefly discussed above, each agent pool has its own scalability and resource needs, and we can use the Total Workload value from above to study the usage trend for each agent pool and understand these needs better.
For visualizing workload trends, for Function 1, we used the TeamCity server’s build APIs to identify active agents and idle builds and GCP’s Managed Instance Group APIs to count the total number of agents. By collecting this data over a period of a few weeks, we were able to identify the trends for each agent pool and configure the maximum number of agents, resource types, and autoscaling thresholds accordingly.
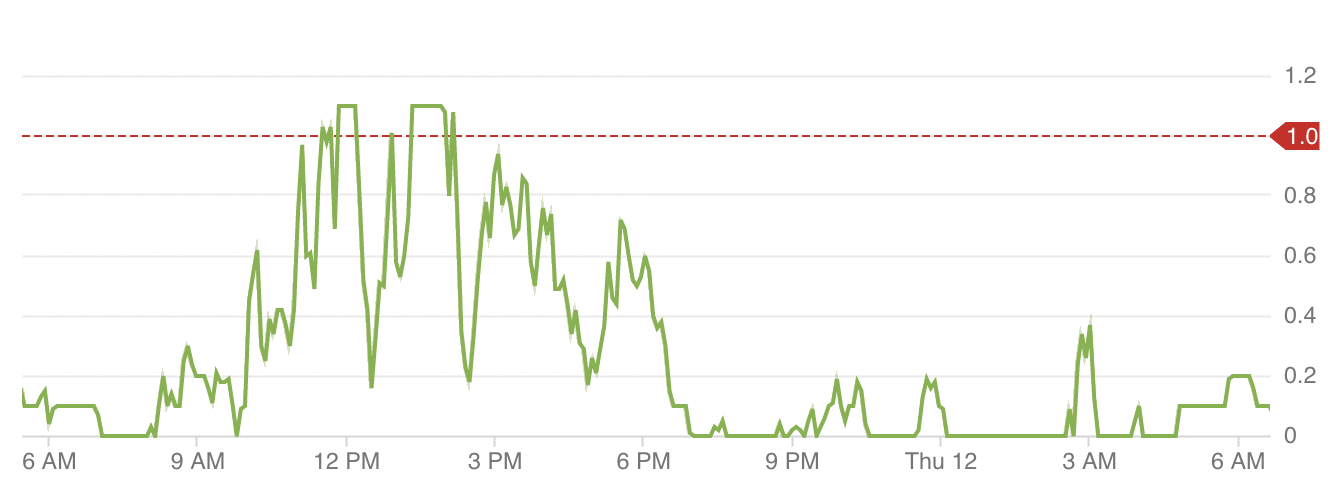
Data 1: Agent pool with dense and busy workload throughout a single day (y-axis is the total workload)
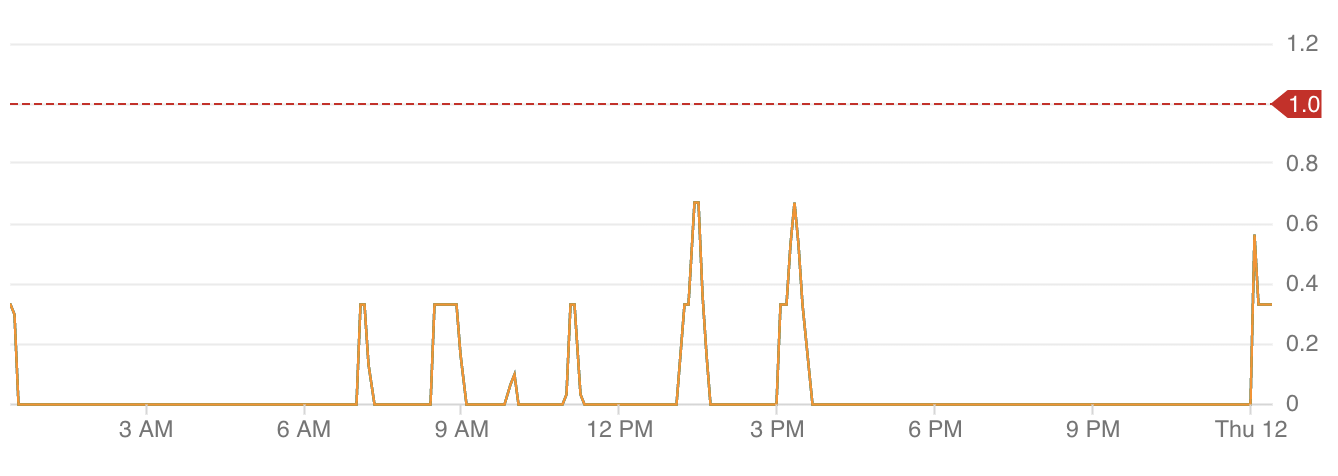
Data 2: Agent pool with sparse workload throughout a single day (y-axis is total workload)
Using Stackdriver’s Custom Metrics, chosen for reasons we get into in the next section, we identified two workload trends:
- Agent pools with busy hour spans throughout a single day (Data 1).
- Agent pools with more sparse and spikey workloads (Data 2).
These were the two extreme cases with the rest of the agent pools having a total workload somewhere in between; a lower total workload average and smaller spikes throughout a given day, e.g. Data 3.
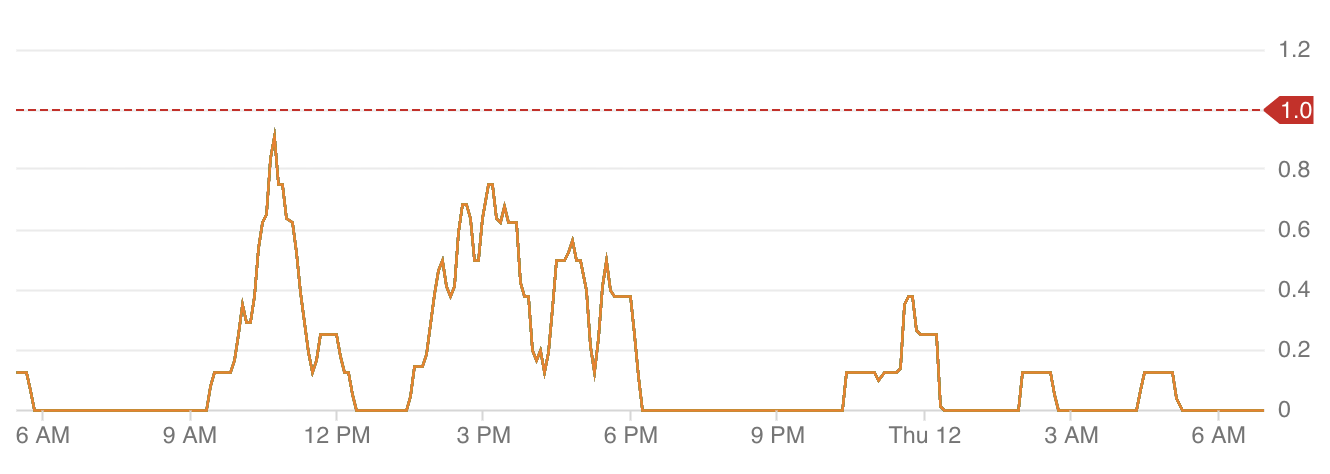
Data 3: Agent pool with busier and sparse workload throughout a single day (y-axis is total workload)
This is where it became clear to us that we could save resource cost on agent pools’ quiet hours, and also decrease the amount of time builds had to wait in the build queue before getting executed at busy hours. This would mean increased developer productivity for us as developers would wait less time to get their build results.
Testing grounds
Once we knew how our agent pools behaved, we built a testing ground to test our candidate autoscaling designs. We opted for simulating the agent pools’ workload as opposed to shadowing the live workload, mainly because we understood how our CI/CD pipelines worked, making it simpler to simulate the more complex scenarios that might be a corner case for an autoscaling system.
Based on the definition of the total workload in Function 1, the simulations primarily focused on mimicking the running time and build chains, and for simplicity, we steered away from resource level metrics and usages. The focus was the number of available build agents at busy hours, and avoiding as many idle build agents as possible at quiet hours.
Distributed autoscaling
Using the tools at hand, we had a few ways of approaching the design for autoscaling our agent pools for our CI/CD system. We spent some time designing around a cloud-native approach that would use the native services distributed across the GCP environments that host the agent pools.
We’d like to take a look at the details of a distributed autoscaling approach that can be modeled in two ways. This section goes over the details of this approach, and the studies we did around the different models.
Design principles
Since we were already configuring Managed Instance Groups (MIGs) to manage our agents pools, our initial designs leveraged the GCE autoscaler that’s natively supported for GCE instance groups.
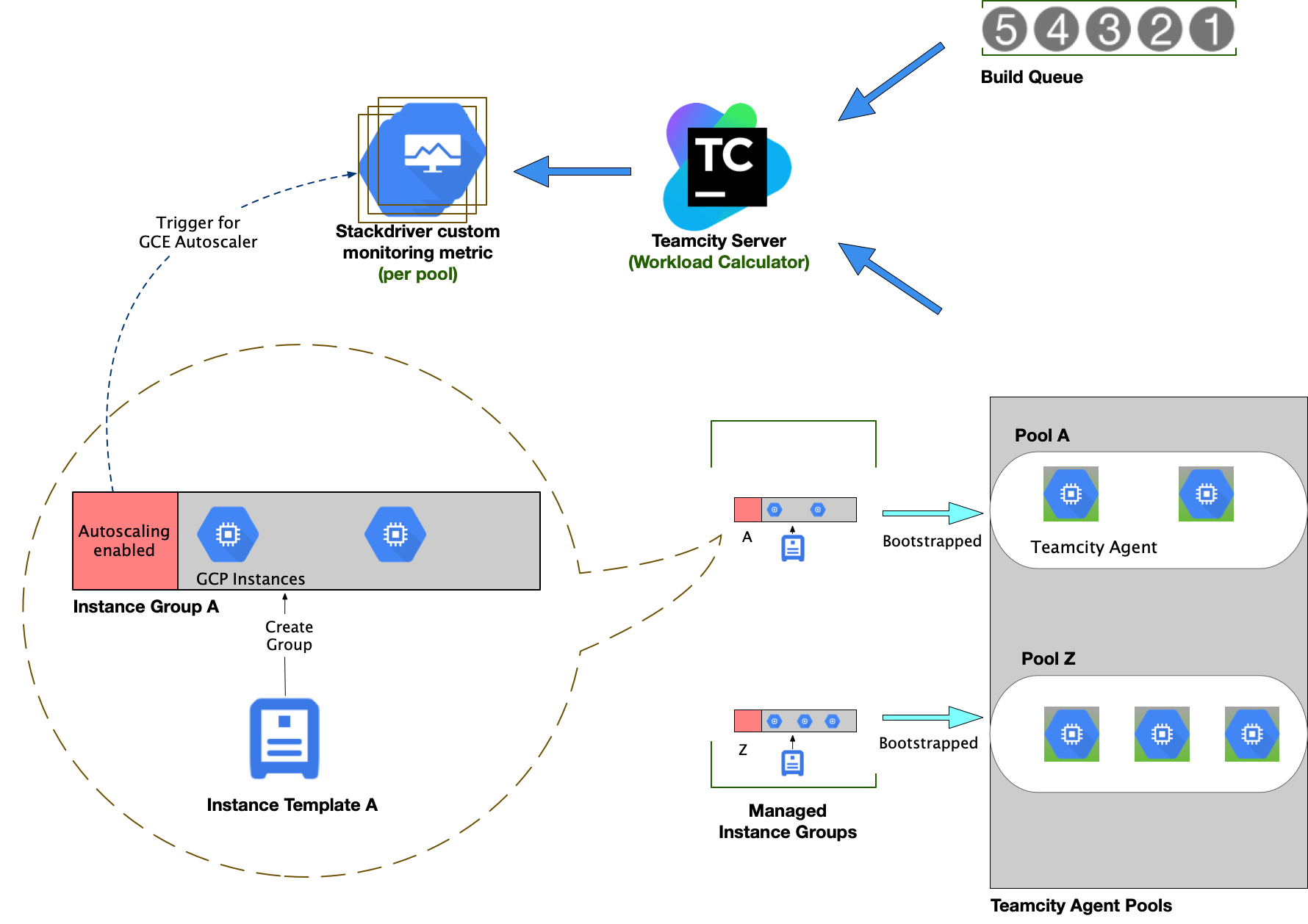
Figure 5: Managed Instance Group autoscaling using Stackdriver Custom Metrics
As illustrated in Figure 5, a generic autoscaling system involves the following components for watching and triggering any scaling event:
- Calculation of a Total Workload on a system, as described earlier.
- Communication of the total workload with an autoscaling scheduler.
- A bootstrapping mechanism to promote instances to build agents, on scale up events.
GCE autoscaler configuration
A Managed Instance Group in GCE is configured to autoscale using Stackdriver monitoring that relies on per-instance custom metrics. We cannot rely on resource level metrics since the lifecycle and activities of the build agents are managed by the TeamCity server, and not symmetrically mapped to resource level metrics in GCE. For example, a build job might have a low or no CPU activity that might trigger a scale down event, if CPU metrics were used for scaling down build agents.
Our autoscaler configuration would use the per-instance aggregation of type GAUGE to average out the utilization for a given MIG based on the Total Workload metrics reported by the TeamCity server. Target utilization on the MIGs are set based on a metric domain, along with a number of maximum replicas per group, mapped to an agent pool.
Stackdriver custom metrics
The autoscaler configuration expects the metrics being pushed to Stackdriver to be a valid utilization metric generated by the monitored resources themselves. This means that each instance in a group must generate their own metrics, with the proper Stackdriver types and labels.
The metrics generated for each group should reflect the utilization of the agent pool at any given time. Hence, we used the Total Workload as a suitable metric that drives the autoscaling events for their respective pools. In this case, the TeamCity server acts as a controller, responsible for calculating the workload, and periodically pushes them into Stackdriver for each instance in an agent pool. If the published workload exceeds or drops below a certain configured threshold, the autoscaler concludes to, respectively, scale up or down the total number of instances of each agent pool serving jobs from the Job Queue.
Design 1
With the autoscaler setup in place as shown in Figure 5, we needed to bootstrap the new instances that get created by the GCE autoscaler. One way to watch the autoscaling events in GCE is the logs written into Google Stackdriver by the GCE autoscaler.
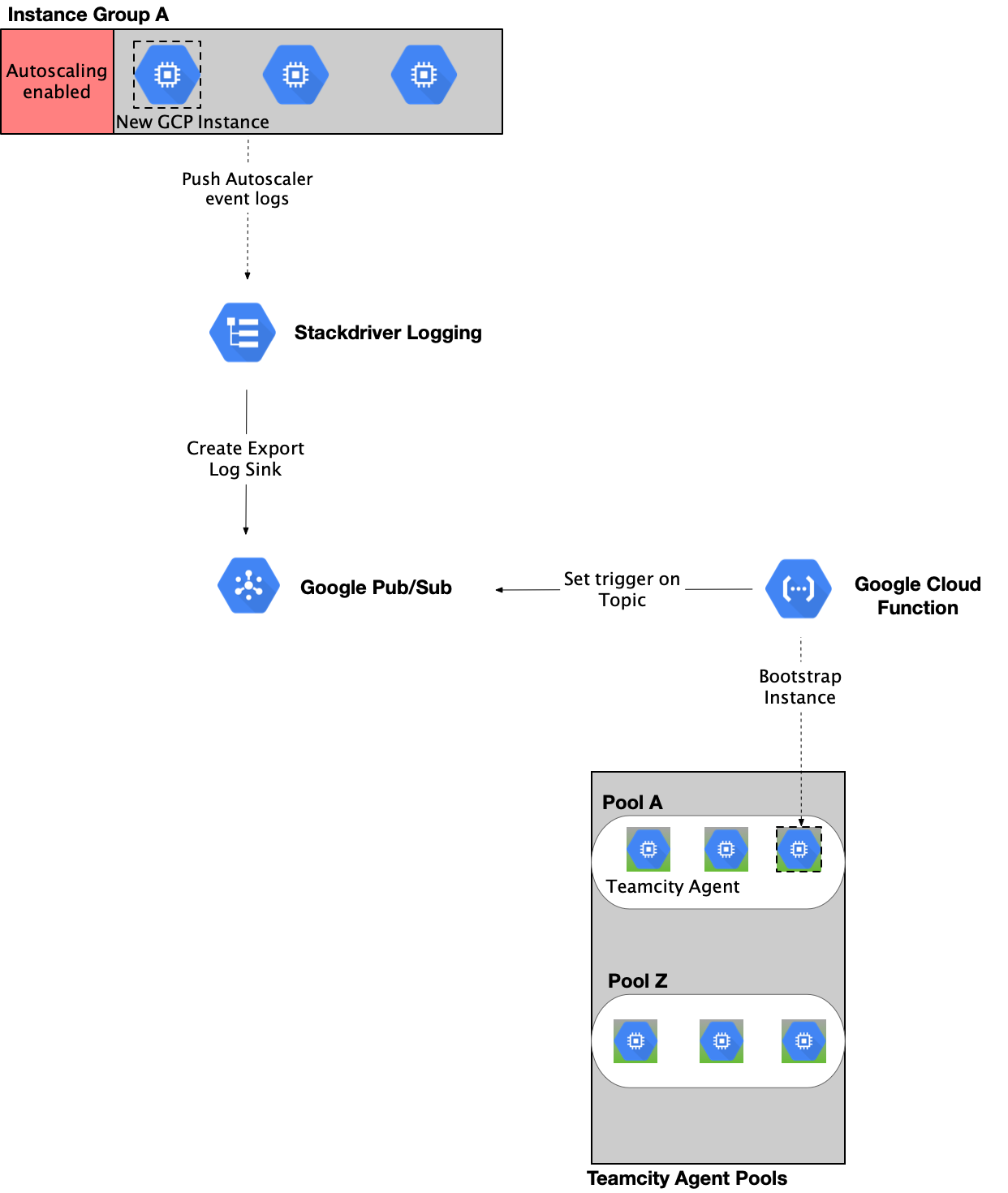
Figure 6: Flow of control in a scale-up event from a Managed Instance Group
As demonstrated in Figure 6, each autoscaler event can be funneled into a Google Cloud Pub/Sub topic from Stackdriver by configuring an Export Sink. We relied on background Google Cloud Functions to perform any bootstrapping or tear down instructions for the build agents depending on the type of scaling activity. These instructions were set to be triggered on messages published to the configured Cloud Pub/Sub topics.
Areas of concern
- Control and visibility: The integration of multiple asynchronous cloud native applications into the CI/CD chain can lead to a decreased level of control on the system. This also means that we do not have an overall view of how each autoscaling activity affects an Instance Group.
- Operational maintenance: The system needs to maintain multiple cloud components, each with their own life cycles. Debugging for an issue in the chain can be cumbersome.
- Logging: Heavy configuration will be required to combine logs from all the entities in the system chain into a centralized logging source for the autoscaling activities.
- Bootstrapping: Cloud Functions are configured to be triggered on autoscaling events created by a GCE autoscaler. With this setup, there is no native way to know when the autoscaler event has completed. Eg: If the autoscaler activity involved increasing the Instance Group size from 2 to 4, there will be events in Stackdriver Logs for each increase in size for the group ( 2 → 3, 3 → 4) but no additional event denoting the completion of this activity as a whole. Since bootstrapping is expected to run against all the newly created instances at once, it is essential that the instances be in a running state when the flow reaches the Cloud Function. This means having complex retry logic involved within the Cloud Functions to wait for the Instance Group to be in a stable state before proceeding to bootstrap. A further optimization will involve separating out the tasks into multiple cloud functions for code maintenance. Overall, this is not a very desirable approach as Cloud Functions are expected to be used as fire and forget serverless APIs and we will be adding a lot of overhead into controlling their life cycles.
Design 2
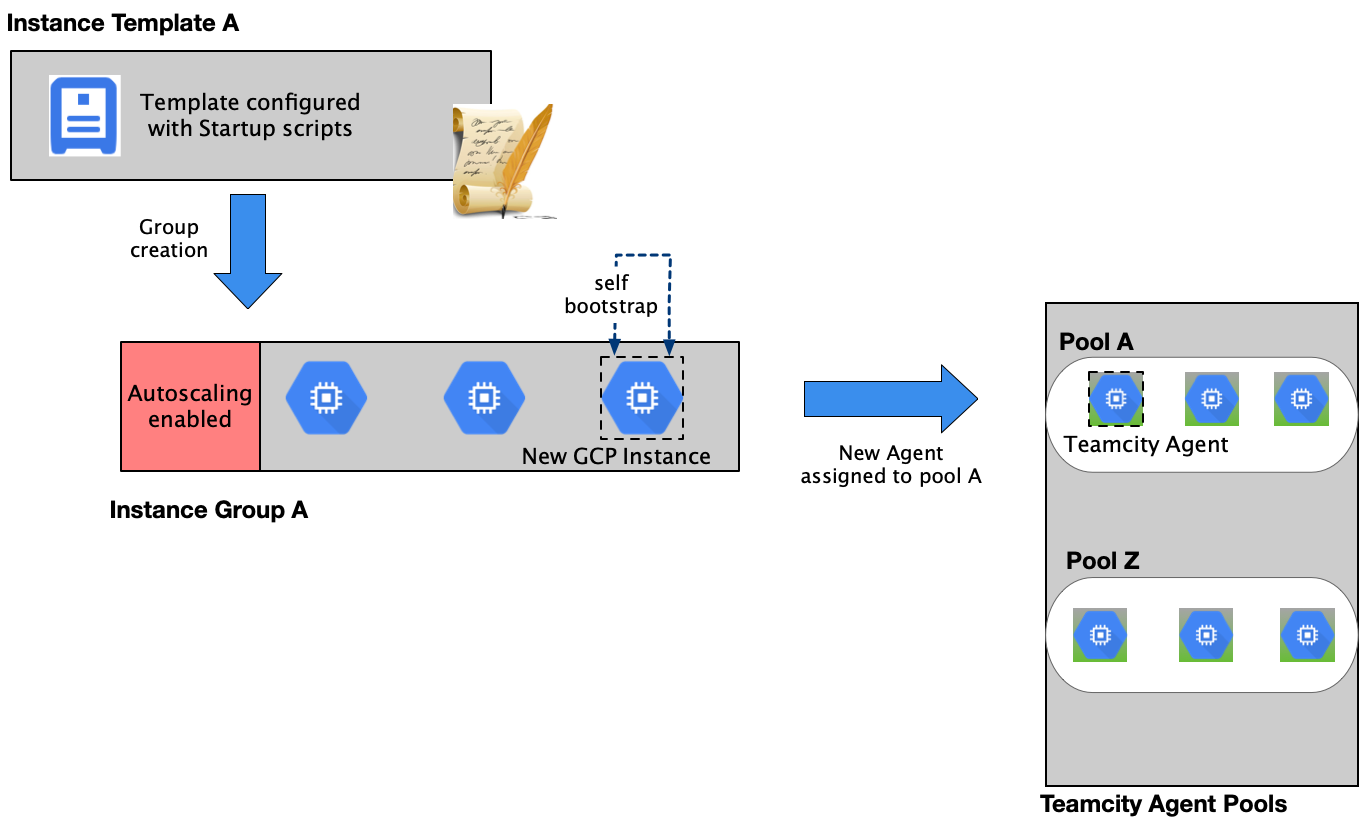
Figure 7: Self bootstrapping of agents with startup scripts during a scale-up activity for the Managed Instance Group
After studying the pain points of Design 1, we knew that we could improve the solution by reducing the number of asynchronous chains in the system and focusing on a more efficient approach to bootstrapping the autoscaled instances. The two points are closely linked since we looked to Cloud Functions as a serverless bootstrapping entity triggered on log events sent out by the GCE Autoscaler.
The solution to this was to keep bootstrapping as close to the autoscaling event as possible, better yet on the instance itself separated from the CI/CD system. We found that this can be achieved with the help of Google Cloud Instance’s startup scripts. These scripts are run at the time of instance startup and they could be programmed to execute all the steps required for the instance to become a Teamcity Agent. We could further configure these startup scripts to leverage the Instance Template custom metadata attributes, using them as bootstrapping parameters for each Instance Group/ Agent Pool. Thereby, in a scale-up event, the new instances always control the bootstrapping while scale-down events are handled natively by the corresponding Google Cloud Instance Group.
Areas of concern
- Erratic scale-down behavior: With the Managed Instance Group Autoscaler configuration, we were able to properly trigger scale up and down the way we intend to do, but on scale downs, instances with activities, e.g. CPU, or custom defined load (active teamcity builds), were being killed in the middle of work. Upon investigation, we found that the determination of which specific instances to kill on scale down is based on the monitoring data aggregated over a time period. Since autoscaling for the Instance Group is based on a single metric for the entire group, all instances were considered equally valid to shut down.
- Autoscaling scheduler: While our architecture tried to integrate the CI/CD pipeline tool and the native cloud framework’s autoscaler, it was still an inefficient solution since we were relying on the life cycles of two disparate entities.
Conclusion
Our distributed autoscaling designs were based on utilizing GCP supported services including the GCE Autoscaler as the autoscaling scheduler of choice. With this we could gain full visibility into how each autoscaling event affects the agent pools’ Instance Group in one place.
On the other hand, there are still some shortcomings with this approach:
- Complexity: The system became more complex, and in some situations or system events, performance may be affected where there is an integration between the CI/CD’s internal events with the autoscaling events. This is mainly visible where there’s API integration from cloud to CI/CD and the workload calculation can’t happen fast enough to trigger the right scaling events.
- Maintenance: Distributed autoscaling configuration had to be maintained across all available agent pool environments, e.g. build, testing, etc.
- Portability: We could not have a generic autoscaling solution that could be ported to a different cloud provider. A Cloud-specific autoscaling orchestration means orchestration must be implemented in each supported cloud.
Based on these findings, we deemed it necessary to research other ways of building the state-of-the-art autoscaling system for our CI/CD system. Hence, we designed a centralized autoscaling process that we’ll tackle in the upcoming second part of this post.