
Balancing the Books at Scale
As a payment processing company, reconciliation, or making sure all of our payments add up, is one of WePay’s foremost concerns. We need to know where all the money is, all the time. This is more easily said than done; we process billions of dollars each year, in hundreds of different flows. To make matters more complicated, as WePay grows and offers new products, not only do we have to deal with the payments we process, but also with new integration methods that skip our internal payments-engine entirely. For example, some of our customers register through WePay, but process all of their payments directly through Chase.
It’s relatively easy to track most of our internal flows, but with multiple downstream payment-processors, batch files from banks, settlement files, and numerous other data-sources, keeping the books balanced becomes a nontrivial problem. In order to keep offering new products and flows, we need a flexible, maintainable, and reliable daily reconciliation system.
Background Accounting Knowledge
WePay, like most companies, uses a double-entry bookkeeping system in which every money-movement is recorded by a corresponding set of debit and credit entries to two (or more) different accounts. We define a number of general ledger accounts (GL accounts) corresponding to various states of money-movement. These don’t represent actual bank accounts, just a logical separation of whose money is where. For example, we have a Merchant-Liability GL account which represents the amount of money WePay owes to merchants using WePay as a payment-processor. When a $100 payment is approved by WePay, we credit this liability account $100, the amount we owe to the merchant, and, in turn, debit an asset account by $100, the amount we’re owed by our downstream processor. These two entries effectively cancel each other out. This keeps the fundamental accounting equation balanced:
Assets = Liabilities + Equity
There are plenty of great blogs and resources about accounting, so I won’t go into too many details here. The main takeaway is that each class of money-movement in our system has an associated debit/credit pair between two GL accounts. This allows us to trace back any missing money to any of the individual money-movements which constitute a transaction.
Our solution
The main double-entry bookkeeping journal-entry system is relatively simple. We use Apache Airflow to handle our scheduling, which includes a number of alerts if things go wrong. Over 100 queries track the entire lifecycle of every money-movement. As soon as a payment is completed in our system we start recording ledger-entries. Additional entries are recorded as we get files back from downstream processors, and then once more when we get statements from the bank.
Each of these entries are calculated daily and persisted in BigQuery, for record-keeping purposes. After this system of queries has completed, the results are sent to a microservice which maps each of these entries to logical GL credit/debit pairs. For example, all of the payment-processing fees which WePay incurs are combined into one GL account: CostOfRevenue. These entries are then coalesced into one cohesive daily report. This report is persisted in Google Cloud Storage, sent to WePay’s internal reconciliation team, and uploaded to Chase’s internal bookkeeping system.
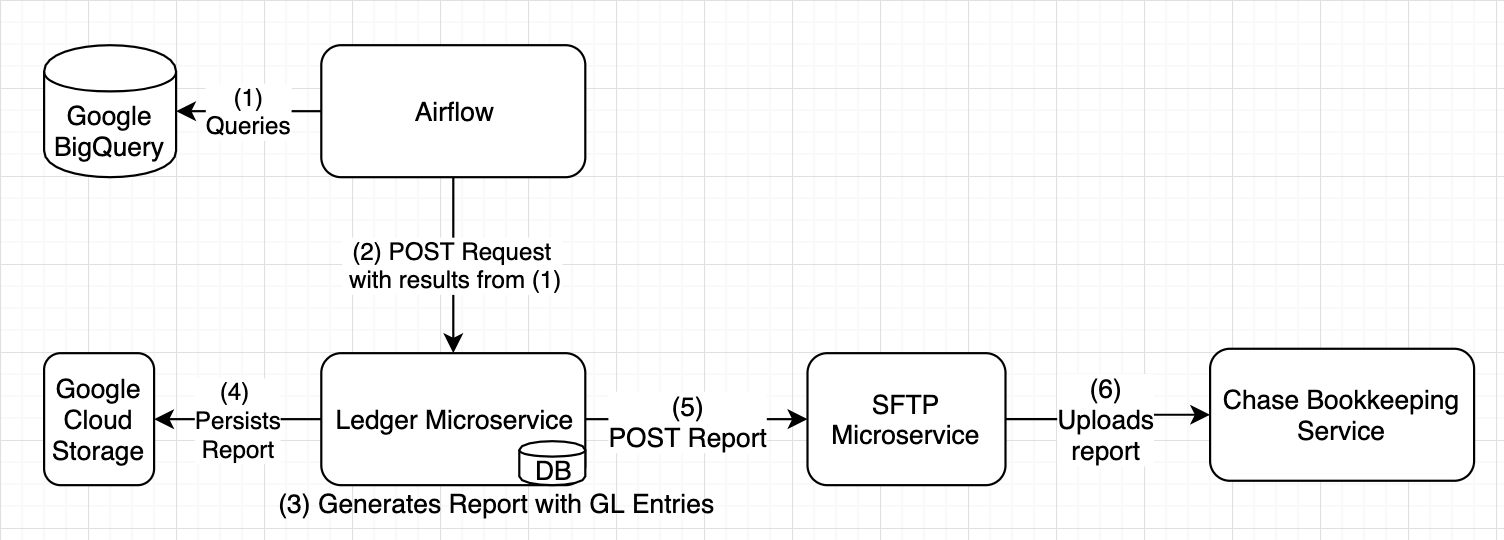
Figure 1: System architecture and flow
This modular system decouples business logic from microservice-implementation. This enables us to account for new features and flows without making code changes. It also allows us to easily make changes to queries and regenerate older reports, in the case of any past misprocessings.
The reconciliation system also has a number of smaller supporting components:
-
Subledger Reports (substantiating the GL accounts)
Our ledger-entry queries are a low-level representation of specific kind of money-movement, e.g. processing fees. As such, they have no knowledge of the overall system; any number of ledger-entries can feed into the same GL account. Because of this, we maintain additional reports, called subledger reports, which provide daily substantiation for each account on a much more granular level. If a GL account is missing $0.01, our subledger reports allow analysts to quickly diagnose the issue by examining each of the payments which fed into that GL account for the day.
-
Variance Detection (intra-payment problems)
Our ledger-system tells us exactly what happened, but, by design, it doesn’t tell us what should have happened. For example, we’ve seen downstream processors errantly double-process payments. To the bookkeeping system, this moves money from one GL account to another, but doesn’t immediately present itself as an error. To combat this, we have a number of systems which follow a payment’s lifecycle from start to finish, double-checking amounts, and examining the clearing patterns for each GL account. This system alerts us to any misprocessings, internal or external.
Ingredients
A number of ingredients made this next-generation daily reconciliation system possible.
-
Near-real-time Data-infrastructure
Our data-warehousing solution, Google BigQuery, was the logical persistence layer for our daily reconciliation reporting. It’s incredibly fast, even on the terabytes of data we need to process each day, and it doesn’t interfere with our actual payment-processing. Obviously we can’t account for a transaction if we can’t read the transaction, so all of our payments, and related data, must therefore arrive in this data-warehouse before our daily reconciliation system can run. WePay currently uses Airflow for the majority of this ETL pipeline; data is extracted every 15 minutes and loaded to BigQuery on an ongoing basis. The remaining data is streamed, largely via Kafka, into BigQuery on a continuous basis.
Our Data-Infrastructure team is currently redesigning the entire ETL pipeline to further improve this 15-minute scheduled transfer to a continuous stream using Debezium, Kafka, and KCBQ, our open-source Kafka-to-BigQuery sink connector. Under this new system, Debezium, an open-source change data capture software, streams change data from our MySQL databases into Kafka. We’ve enabled log compaction on these Kafka-topics, to enable bootstrapping new services from these streams, and to facilitate rebootstrapping in the case of any issues. KCBQ then reads these streams and persists them to BigQuery. Once this new pipeline is finished, WePay will be able to provide real-time reporting that almost instantly reflects the underlying data.
-
Reliable Scheduling Solution
We use Apache Airflow, a great open-source scheduling solution. Any scheduling solution will work, but the ability to define individual tasks and dependency-graphs has facilitated a healthy modularity. Additionally, BigQuery is prone to intermittent errors, so the automatic retries and inter-task dependencies have proved advantageous.
-
Data-Quality
Data-Quality Concerns, such as duplicates or delayed data, are easy to overlook when building a reconciliation system. Carefully considering our data-pipeline uncovered a number of potential issues which would otherwise have resulted in misreporting.
We saw a few main problems:
1) Our kafka-pipelines generally use an at-least-once configuration; how do we make sure we report on each transaction exactly once?
Timestamp-based deduplication. Using a primary key we take the earliest transaction we see, and disregard all following duplicates. This diverges from the customary deduplication solution, which discards all rows but the most-recent. Because we run on a scheduled interval, the customary deduplication scheme will double-report any duplicate records that cross time-boundaries. For example, if we see a $100 transaction on day 1, report on it, then this transaction gets errantly duplicated on day 2, the typical deduplication scheme would lead us to report on this transaction for a second time.
2) Append-only tables: every change to a record will result in an entire duplicate of the record being inserted. How can we make sure we’re not double-reporting?
Append-only tables are largely desirable for reporting applications. They won’t overwrite historical information, which may be important to some reports. However, typical append-only tables will re-insert the entire row each time a field is changed. When some small, irrelevant, piece of information changes, and a new (mostly-duplicate) row is inserted, how do we prevent re-reporting this row? A strong underlying money-movement state-machine was the key to solving this problem. Essentially we should only report on transactions that are in a terminal state, and won’t be modified at all in the future. This means that payments that are later reversed or refunded need to be entirely separate items in our state-machine.
3) Delayed data: when our pipeline experiences delays, or worse, when an external source is delayed, how do we make sure we report on these records as soon as they’re available?
Our reconciliation system uses two classes of timestamps: insert-time, or when a record is available in our data-warehouse, and the actual payment-time, or when a money-movement is considered to have been completed. Our reconciliation system uses the former to ensure that we do not miss delayed records. Essentially, records are reported on as soon as they’re available in BigQuery, even if the actual payment occurred several days prior. We use the latter to ensure accurate reporting. Even if a payment did not enter our data warehouse for several days after occurring, we know exactly when each payment was actually completed.
Alerting & Monitoring
No software solution would be complete without a good monitoring set up. We’ve added a variety of alerts to our system, which alert us at the first sign of any trouble. Based on the severity, these alerts will trigger an email, send a Slack-alert, or even page our on-call engineer.
- File-generation check: A daily scheduled job which ensures a file was generated. Our microservice records a row once a file has been successfully generated. An Airflow job checks that this row has been added each day.
- An SFTP-connectivity monitor: Our service is tasked with uploading a generated file to the Chase bookkeeping software. We’ve seen a few issues with this SFTP connection, so we added a generic SFTP-connection testing job, which verifies end-to-end connectivity with a destination server. This gives us an early warning for any connection issues, like deprecated encryption keys, or altered firewall rules.
- ACL monitoring: A number of our reconciliation reports depend on GCloud service accounts with proper access to particular resources. Sometimes these ACLs can get errantly modified. To monitor this, we’ve added an alert which, using metadata access, ensures each of our service-accounts has the exact permissions that it needs.
- Log-monitoring: A lot of our other alerts are scheduled via Airflow. In order to avoid having a single-point of failure, we added an alert which periodically checks the logs, using Elastalert. This ensures that we’ll be alerted to any file-generation issues even if Airflow is hard down.
Future Improvements
-
Canonical Data Representation: Data-formats change. How do you insulate your reporting system from underlying data-schema changes? A canonical data model. This is the goal of one of our current projects. By building on top of a canonical data model, dealing with any schema changes becomes as simple as writing new mappers. Additionally, we can proactively filter out any data-quality concerns like duplicated or malformed records.
This isolation will give us a lot of benefits – if the processing flow, or upstream data-schema, changes, for whatever reason, our system will still perform well on our tried and tested format. And by doing data-quality checks ahead of time, all of our reconciliation reports can safely assume that the underlying data has no quality issues. In contrast, without this model, every single one of our reporting and reconciliation products would have to individually handle data-format changes and data-quality concerns.
Results
So far the new daily reconciliation system has allowed us to add a number of new accounting flows with minimal work. We’ve seen multiple products added with zero impact on our books. When things do go wrong, internally or externally, we know exactly where - the bug-diagnosis and resolution process has never been easier.
One external issue we’ve recently discovered was a malformatted returns file. This file is sent to us by our downstream processor to let us know when payouts were unable to complete successfully. This file lets us know to move money back into our asset GL account, until the issue can be resolved. Our daily-reconciliation system immediately notified us that there had been an issue with the returns file. Because our new system runs on a faster cadence, with more granularity, we were able to pinpoint the source of the issue that same day, and reach out to our payment processor.
Another issue we’ve uncovered, this one internal, was the misprocessing of NOC files. These files are used to make changes to bank-account information for eCheck payments and payouts. A certain combination of fields would render our processor-integration microservice unable to parse them. This kind of issue is potentially costly. If our internal information isn’t corrected in response to these files, we may fail to process certain payments. Larger processing issues often present themselves slowly at first, but under our new daily reconciliation system, even small variances get immediate attention. Our new system detected the very first ocurrence of this issue, an inconsistency of just $4.54, and the team was able to promptly fix the underlying problem.