
Waltz: A Distributed Write-Ahead Log
We are happy to announce the open source release of Waltz. Waltz is a distributed write-ahead log. It was initially designed to be the ledger of money transactions on the WePay system and was generalized for broader use cases of distributed systems that require serializable consistency. Waltz is similar to existing log systems like Kafka in that it accepts/persists/propagates transaction data produced/consumed by many services. However, unlike other systems, Waltz provides a machinery that facilitates a serializable consistency in distributed applications. It detects conflicting transactions before they are committed to the log. Waltz is regarded as the single source of truth rather than the database, and it enables a highly reliable log-centric system architecture.
Background
Databases
The WePay system has been constantly growing to handle more traffic and more functionalities. We split a large service into smaller services to keep the system manageable when it makes sense. Each service typically has its own database. For better isolation it is not shared with other services.
It is not trivial to keep all databases consistent when there are faults such as network failures, process failures, and machine failures. Services interact with each other over the network. Interactions often result in database updates on both sides. Faults may cause inconsistencies between the databases. Most such inconsistencies are fixed by daemon threads that perform check-and-repair operations periodically. But not every repair can be automated. Sometimes manual operations are required.
On top of this, databases are replicated for fault tolerance. We use MySQL async replication. When the primary region goes down, a region failover will happen, and the backup region will take over the processing so that we can continue processing payments. Multi-region replication has its own issues. A database update in the master database will not appear in a slave database instantly. There is always a latency, and replication lags are the norm. There is no guarantee that new master databases have all up-to-date data nor that they are in sync with each other.
Stream Oriented Processing
We employ asynchronous processing in many places. We want to defer updates that don’t require immediate consistency. This makes the main transactions lighter and improves the response and throughput. We do so by using a stream oriented processing with Kafka. A service updates its own database and writes messages to Kafka at the same time. The same service or a different service asynchronously performs another database update when it consumes Kafka messages. This works well, but the drawback is that a service has to write to two separate storage systems, a database and Kafka. We still need check-and-repair.
Basic Idea
Waltz is what we describe as a write-ahead log. This recorded log is neither the output of a change-data-capture from a database nor a secondary output from an application. It is the primary information of the system state transition. This is different from a typical transaction system built around a database system where the database is the source of truth. In the new model, the log is the source of truth (the primary information), and the database is derived from the log (the secondary information). Now the challenge is how we guarantee that all data in our databases are consistent with the log, and also that all data in the log are correct in terms of serializability.
How do we guarantee databases and the log are consistent? It is relatively easy to achieve an eventual consistency because transaction records are immutable and ordered in the log. If an application applies the transactions to its own database in the same order, the result should be deterministic. Let us describe this basic idea.
- An application composes a transaction message that consists of descriptions of intended data change.
- The application sends it to Waltz. At this point, the application’s database is not updated yet.
- Waltz receives the transaction message and persists it in the Waltz log.
- Waltz sends the transaction message back to the application.
- The application receives the transaction message and applies data change to its own database.
The following is an example that the application reads the value of V=x from a database and update it to V=y.
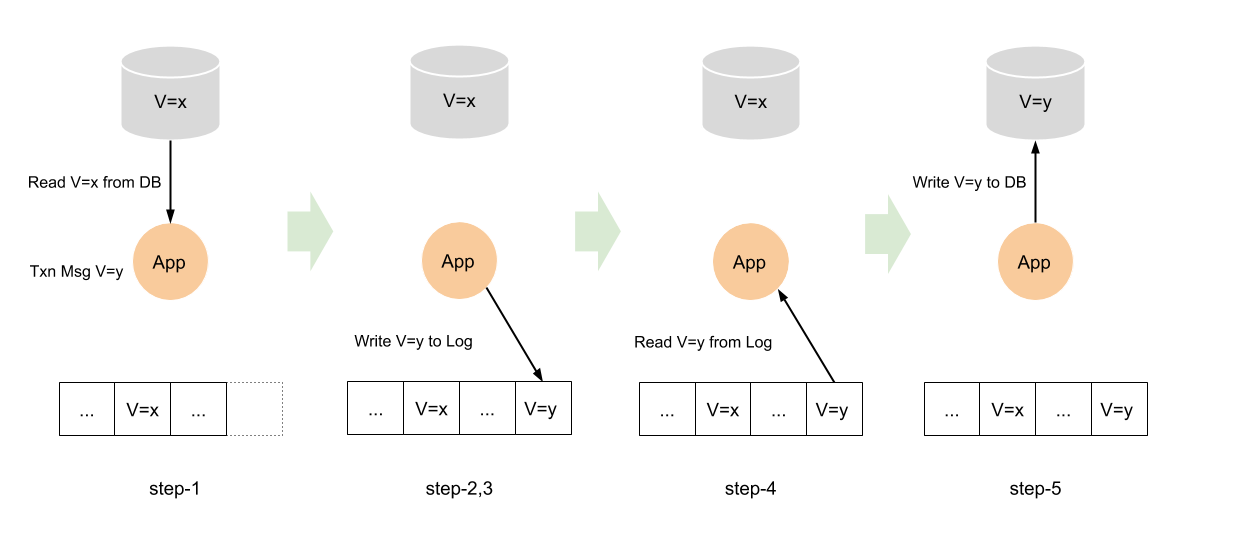
The Waltz log contains all data changes. Updates to application databases are driven by messages (transaction data) from Waltz. So, Waltz is the holder of the primary information, the source of truth. And the service databases are derived information, materialized views of the Waltz log.
This makes applications resilient to faults. If an application failed just before step-5, so the transaction was persisted in Waltz, but the application was unable to update its database, Waltz will send the transaction message again to the restarted application process. The application can recover its database by applying the remaining transaction messages from Waltz.
This design makes data replication and sharing very easy. Waltz allows many clients to read from and write to the same log. A replica can be made by applying the messages from Waltz. And the same transaction data can be used for different purposes according to an application’s needs without changing other applications. It allows us to subdivide a service into smaller services without increasing complexity in communication and coordination.
This sounds all good. But if you think about a distributed environment where concurrent attempts of data updates can happen, you realize it is not easy to guarantee the integrity of data. There may be clients pushing conflicting transactions. If we persist all messages regardless of their consistency, we must rely on post processing for the conflict resolutions. It may do deduplication and integrity checks using a database. It may reject bad messages, inform the upstream services the disposition status of the messages somehow and produce a new “cleansed” log. This adds a complexity to the system design. It consumes more resources and increases latency. In the end, the consistency of the post processing database and the “cleansed” log are still not guaranteed. It is the same problem again. This is a major hurdle to overcome when using existing log systems. That is why we implemented our own log system, Waltz, which prevents the log from getting polluted with inconsistent transaction records in the first place.
Difficulties with Existing Log Systems
Before going into details, we want to illustrate difficulties with existing systems using a simple key-value store backed by a log system.
Difficulty in Read-Modify-Write
To make the log the source of truth, we have to write to the log before updating the key-value store. The service sends the new data to the log system. The service will save the new value to a KV store when it receives the new message from the log. Suppose new data is computed from the existing data in the key-value store (read-modify-write). How do we guarantee that the update is correct? For the update to be correct, the data we read must be the most recent data. The problem is that there is latency, and the data in KV store may not reflect the most recent update in the log.
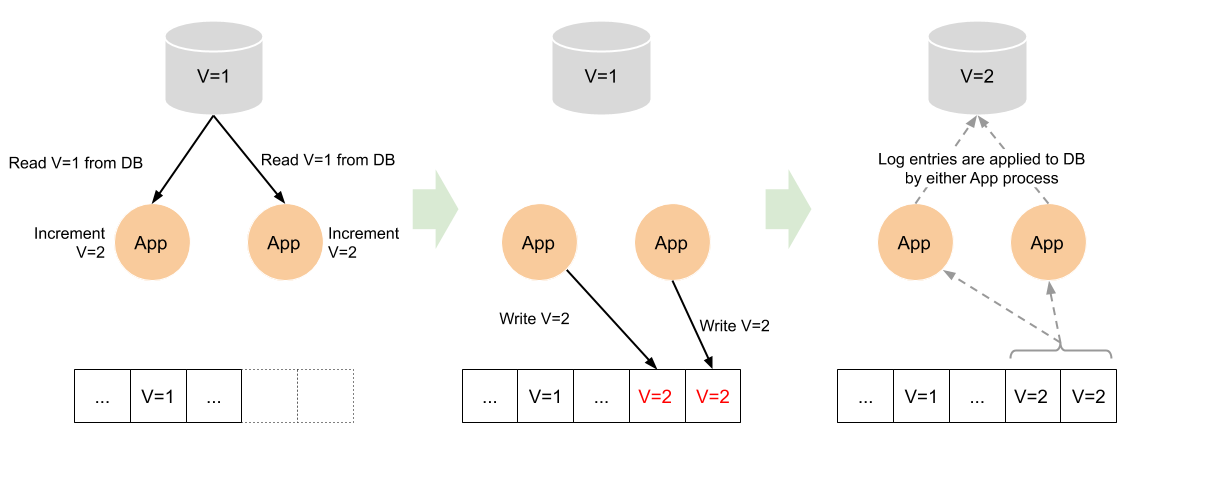
Suppose we have a simple counter service which stores the counter value in KV store.
- An application sends an INCREMENT request to the service.
- The service, then, reads the current value in KV store.
- The service sends “the current value + 1” to the log.
- The service updates the counter value in KV store when it receives the new message from the log.
A race condition happens when the service receives another INCREMENT request at the same time. If step-2 of the second request is processed before the service completes step-4 of the first request, the effect of the first request will be overwritten by the effect of the second request (last-write-wins). As a result, the value is incremented only once for two INCREMENT requests.
Difficulty in Implementing Constraints
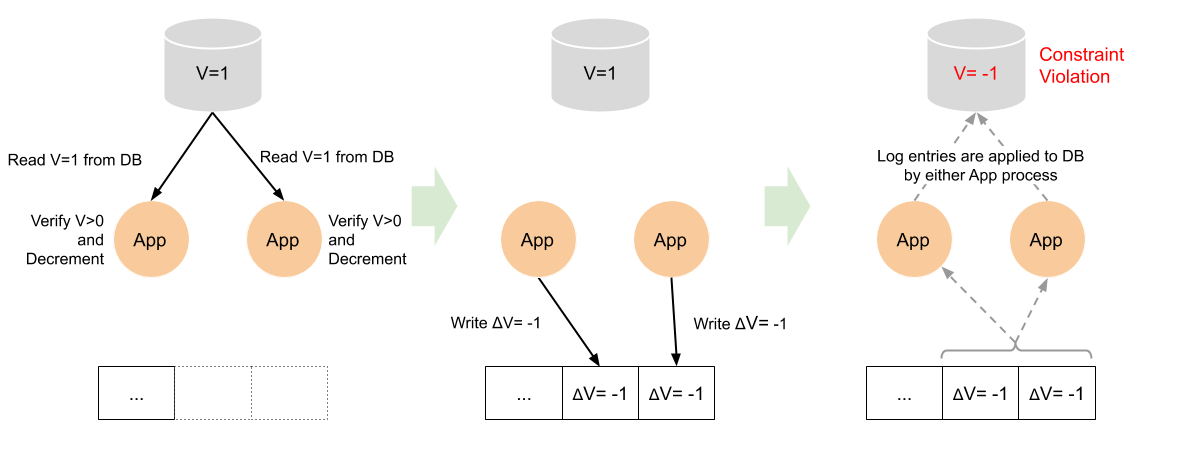
In the above scenario, you may think that the message shouldn’t be the newly computed value but the difference, something like “+1”. As long as the log messages are consumed in single threaded way in the service, the counter value will be correctly incremented twice because the service receives two “+1” messages. Now imagine you need to implement a constraint on the counter value like “the counter value cannot be negative”. The problem comes back. Since there is no reliable way for the service to know the true current value because of a race condition. There is no way to implement the constraint reliably.
Duplicate Messages
Duplicate messages are a big problem. You don’t want the payment system recording duplicate payments for your single purchase. If a write to the log has failed, the application needs to retry, however the application doesn’t have a way of determining where the write failed. The message may or may not have been persisted to the log. The message should be accepted only once by the log system. In other words, the system needs to be idempotent. A simple solution with existing log systems is to attach a unique id to a message and filter out duplicates afterwards. It is a huge burden to retain a map of all unique IDs forever. Usually such systems apply retention policies to reduce the amount of data. The retention periods are set to long enough that false negatives are unlikely. But “unlikely” is not a guarantee. How do we guarantee idempotency?
Our Solution
Waltz solves the above problems by applying a well known method, optimistic locking, to the log system.
Optimistic Locking
An application can attach locks to a transaction message. A lock consists of a lock ID and the mode. Lock IDs are application defined. They usually designate some entity in the real world, like a payment, or an account, etc. But Waltz is agnostic about what IDs represent. An application is free to decide the lock granularity. Waltz supports two lock modes, READ and WRITE. The READ mode means that the transaction is based on the state of an entity that the lock ID designates. The WRITE mode means that the transaction updates the state of an entity potentially based on its current state.
Before explaining how optimistic locking works in Waltz, we need to describe some key concepts in Waltz, the transaction ID, the client high-water mark, the lock table, the lock high-water mark and the lock compatibility test.
A transaction ID is a unique 64-bit integer ID assigned to a transaction successfully persisted. Every time a new transaction is committed, the transaction ID is incremented. The transaction ID plays an important role in the optimistic locking in Waltz.
A client high-water mark is the highest transaction ID that the client application has applied to own database.
Waltz internally manages the lock table which is basically a map from lock IDs to transaction IDs. The lock table returns the most recent transaction ID that a given lock ID was attached to when a transaction message for the lock was in the WRITE mode. This is called the lock high-water mark. (The map is actually a fixed size randomized data structure that gives the estimated transaction ID of the last successful transaction for the given lock ID. The estimated transaction ID is guaranteed to be equal to or greater than the true transaction ID.)
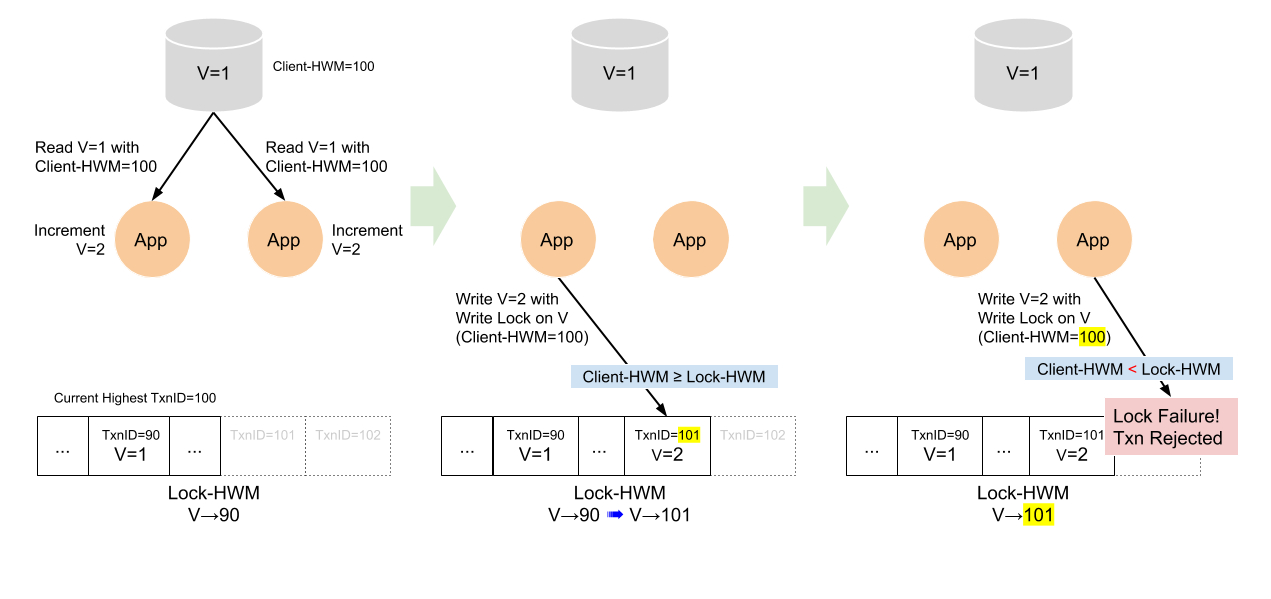
The lock compatibility test is performed by comparing the client high-water mark and the lock high-water mark. For a given lock ID, the lock is compatible if the client high-water mark is equal to or greater than the lock high-water mark.
The following is what happens when a message has a lock ID in WRITE mode is attached.
- A client sends a transaction message. It contains the client high-water mark.
- Waltz receives the message with a lock ID.
- Waltz looks up the lock table and performs the lock compatibility test.
- If the test failed, Waltz rejects the message.
- If the test succeeded, Waltz assigns a new transaction ID and writes the message to the log.
- If the write failed, Waltz does not update the lock table.
- If the write succeeded, Waltz updates the lock table entry with the new transaction ID.
What does a lock compatibility test failure imply? When failed, the client high-water mark is lower than the lock high-water mark. It means the application hasn’t consumed the transaction that updated the lock high-water mark. So, the transaction message was constructed from stale data. It is not safe to accept it.
Race conditions discussed earlier are detected using the optimistic locking. Suppose two clients send the messages with the same write lock at the same time. An interesting case is when their client high-water marks are identical and are compatible with the lock high-water mark. One of the messages will be processed first by Waltz server. It will pass the lock compatibility test because its client high-water mark and the lock high-water mark are equal. After commit, the lock table entry will be updated to the new transaction ID. Now the second message will fail because the lock high-water mark became higher than the client high-water mark.
Limitations and Requirements
Optimistic locking works surprisingly well for our use cases. But it is by no means an omnipotent solution. We have certain limitations and requirements for the application design.
There are no long-lived transactions. A transaction must be packaged into a single Waltz message. A transaction does not span multiple messages. It doesn’t mean that a transaction is limited to a single data operation. An application may construct a single message with multiple data operations that need to be performed as an atomic operation. Such a message is mapped to multiple DML statements performed in a single SQL transaction when consumed by an application.
We require an application to have a transactional data storage like an SQL database. The database acts as a materialized view of Waltz transaction log. The application consumes transaction messages from Waltz and may or may not apply them to the database according to the application’s needs. Waltz does not impose any specific database schema. Applications are free to define their own schema. In addition, the application database must store the high-water mark which is the highest transaction ID the service has consumed.
Other Regular Distributed System Stuff
Cluster
Waltz is a distributed system. A Waltz cluster consists of server nodes, storage nodes and clients. The clients run in application processes. A server node acts as a proxy and a cache between clients and storage nodes. A client sends a transaction message to a server node, then the server node writes it to multiple storage nodes for durability and fault tolerance. ZooKeeper is used for the cluster management. Server processes are tracked by ZooKeeper. ZooKeeper is also used as a shared metadata storage for replica states.
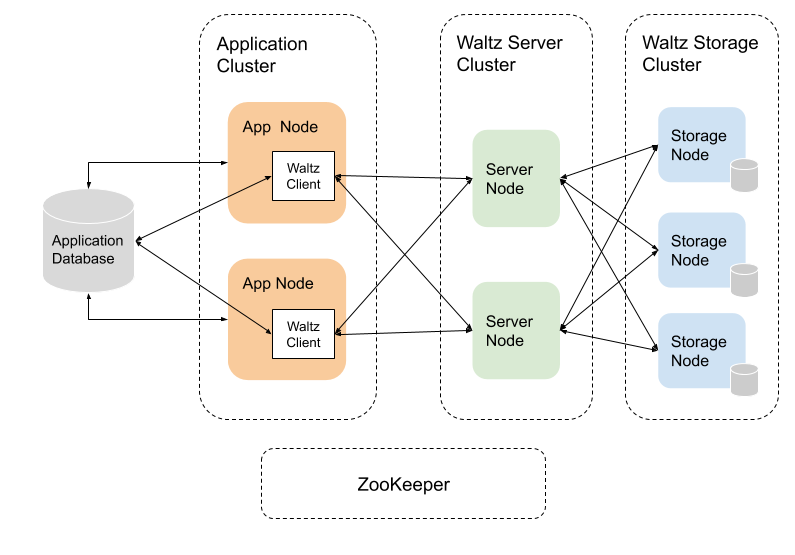
Partitioning
Waltz log is partitioned for scalability. Transaction-to-partition assignment is controlled by applications. Partitions are independent logs. Locks are managed per-partition.
Server nodes are responsible for coordinating writes to storage nodes. Each server node takes responsibility for a subset of partitions. There is exactly one server node responsible for each partition. On a failure of a server node, Waltz automatically reassigns partitions from the failed server node to remaining server nodes and starts a recovery process. Clients are also notified of the partition assignment change so that the subsequent writes will go to the correct servers.
Replication Protocol
Waltz uses quorum writes for log replication. A transaction is committed when a majority of storage nodes acknowledge the success of write. The quorum write is not enough to build a consistent distributed system. Waltz uses ZooKeeper for leader election, unique id generation, fault detector and metadata store. On top of those, Waltz implements a similar protocol as Multi-Paxos and Raft have in order to ensure the consistency of logs in storage nodes.
For each partition, a server is elected as the partition owner who is responsible for read/write of data in the partition. The partition owner election is done using ZooKeeper. The storage nodes are passively participating in the protocol. They don’t even talk to ZooKeeper. Their actions are dictated by the server who is taking the partition ownership.
We store a small amount of metadata about storage states in ZooKeeper, as well. Metadata are used during recovery. The server runs the recovery process after a partition was assigned or after any fault occurred. Write requests from clients are blocked until the recovery completes. After a successful recovery it is guaranteed that a majority of replicas are in sync. Waltz server routes the writes only to replicas in sync, and in the background, continues to repair out-of-sync replicas.
Missing Features and Future Work
Log Management
One of our requirements is to store all transactions as an immutable history. So, we don’t have a log retention policy. There is no deletion of old records. Similarly, we don’t have a key based log compaction like the one found in Kafka. We don’t even have a concept of an entry key. But it is not economic to store all transaction records forever in storage nodes. We will need to implement a facility that allow us to archive old records to cheaper storage.
Topics
Waltz doesn’t have a concept of topics found in Kafka. Waltz is a single topic system. Multi-topic support is not a pressing requirement for now. We’d rather have a better isolation of “topics” by having separate clusters.
Tools
Our administration tool is CLI based. We definitely want to implement a GUI based tool.
Proxy/Cache
We are considering to add a proxy/cache in each region. The benefits of this are faster delivery of transaction data and reduced cross-region calls.
Summary
We developed Waltz, a new open source distributed write-ahead log. In addition to being a highly available and scalable distributed log system, it provides a unique optimistic concurrency control mechanism. It makes it possible for applications to achieve serializable consistency in a large-scale widely distributed environment. We released Waltz as an open-source software. If you are interested, please check out our Git repository.