
Splitting traffic with SplitIO
At WePay we are constantly evolving our core infrastructure to better meet the needs of our customers, whether that’s broadening the feature set for our end users, or delivering faster transactions for our payment processors. As part of scaling, WePay began to transition from a monolithic codebase to a set of microservices. But migrating away from the monolith while maintaining, or exceeding, previous service levels isn’t easy. Our new services will come in completely different languages and take completely different approaches, yet the customer should never see a service interruption during the transition. To facilitate these migrations we decided to take a controlled rollout approach, using Split as our platform for feature flags.
Transitioning to Split
Our monolith comprised all the core services of WePay. We updated it about once a week, sometimes less, shipping all our changes at once, and then watching the logs and monitoring services to see how it went. As part of the release, the same code was rolled out to all of our customers. When something broke in one part of the app, it might necessitate a complete rollback while we worked out the problem—a drain on us and our customers.
A microservices architecture provides us with a streamlined deployment pipeline. Now we’re using Docker containers deployed in Kubernetes clusters. But getting there, jumping from the monolith, meant parsing out each piece as a set of features that would be replaced by a new service. Then, figuring out how to make the jump without causing any degradation or chaos for our customers.
We developed a straightforward feature toggle system in the monolith that we have been using for simple on/off types of deployment, influenced heavily by the original Flickr blog post. It was great for single feature deployment and turning things off and on, but being relegated to PHP, it was useless in adding control to our transition to microservices in Java and Python. We faced a staggering problem: we wanted to take big pieces of code out of the monolith, and while doing that ramp the monolith down, and the new service up, for effectively the same task. In this case, we can’t use a methodology that’s just specific to the monolith, or to the service.
Our goal was to have the same feature, the same experiment, running across multiple languages and controlled from one place. For that we turned to Split. SplitIO is a controlled rollout and feature flagging service that gave us multi-language support, the ability to run the same experiments in our staging and production environments, and the opportunity to manage all of them from one interface. Apart from that, we also love not having to focus engineering time on something that’s not our core competency.
Using Split
Split allows us to create predefined groups of WePay users, or apps, that a feature can selectively target. These predefined groups are called Segments. Although segments are not required, it is helpful when you are targeting a large portion of the user base. For example, one might wish to target a new feature to all the Canadian merchants.
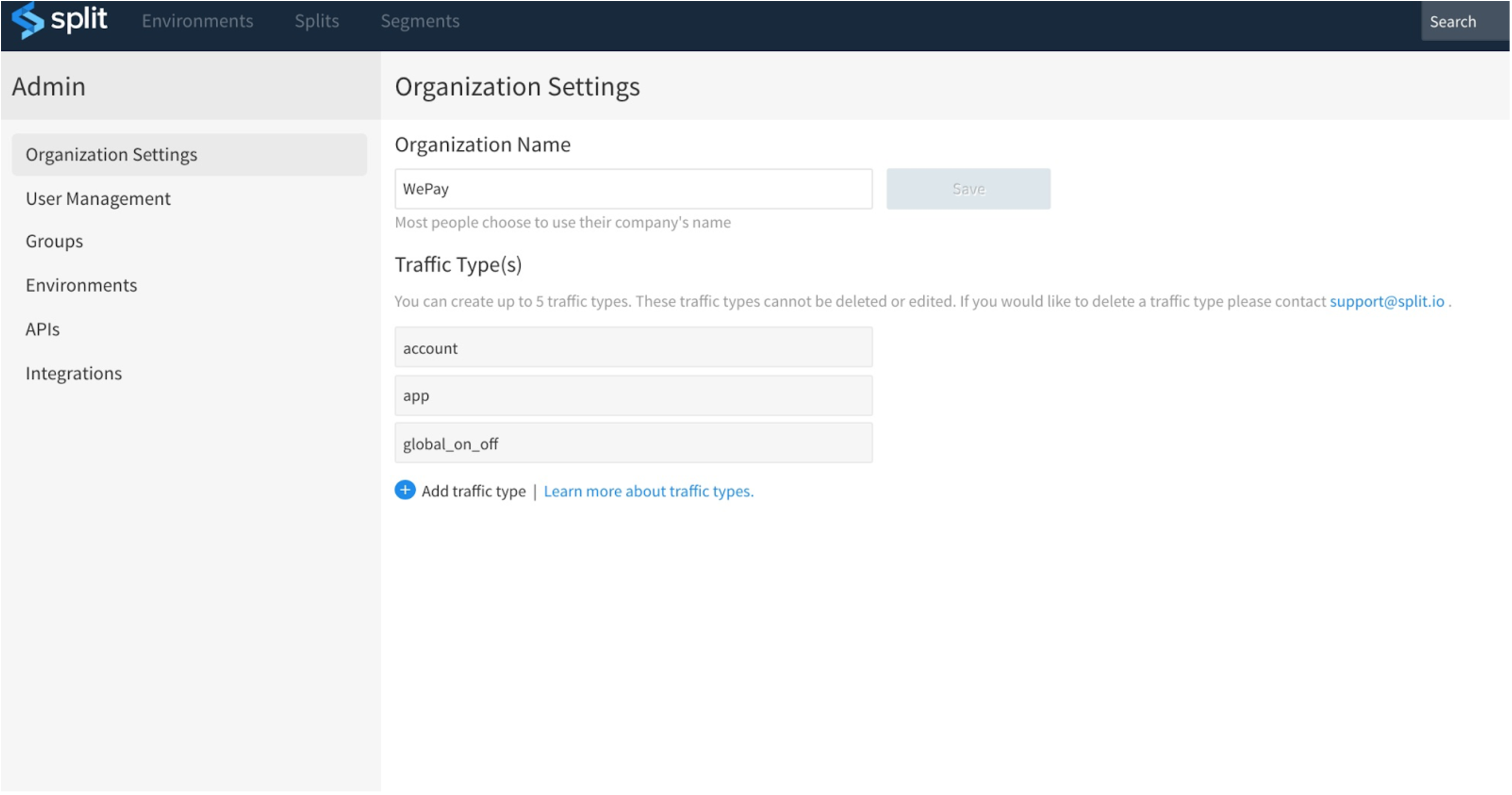
Traffic type is the topmost level of segmentation. At WePay we have three traffic types:
- global_on_off: Applies to all customer traffic. This is useful for on/off type of feature.
- app: This applies to selective WePay apps. Developers can provide a list of app ids for which a specific feature can be turned on/off easily.
- account: Enables a specific feature only for selective merchant accounts based on merchant ids in the segment.
Defining a new experiment involves creating a Split in the split editor and creating a Segment for this experiment.
In the following example, we’ll create a split to delegate the logic for “chargeback email processing” into a new microservice. We want the microservice to do the processing for chargebacks for a set of long tail apps defined in a Segment.
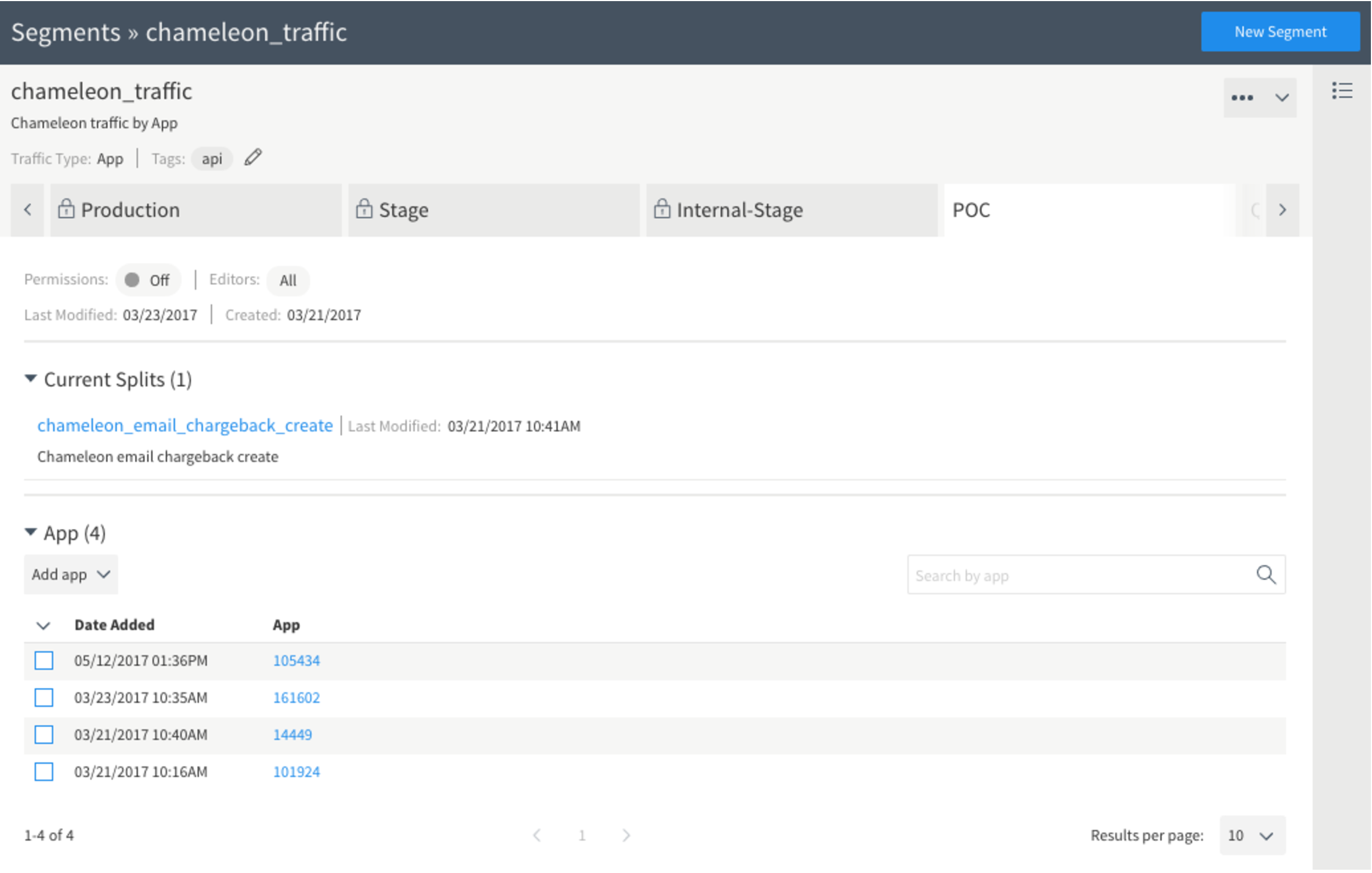
Segments are defined in the segment editor. Here we create a segment called chameleon_traffic. A segment can have different apps, depending on the environment where you are running the experiment.
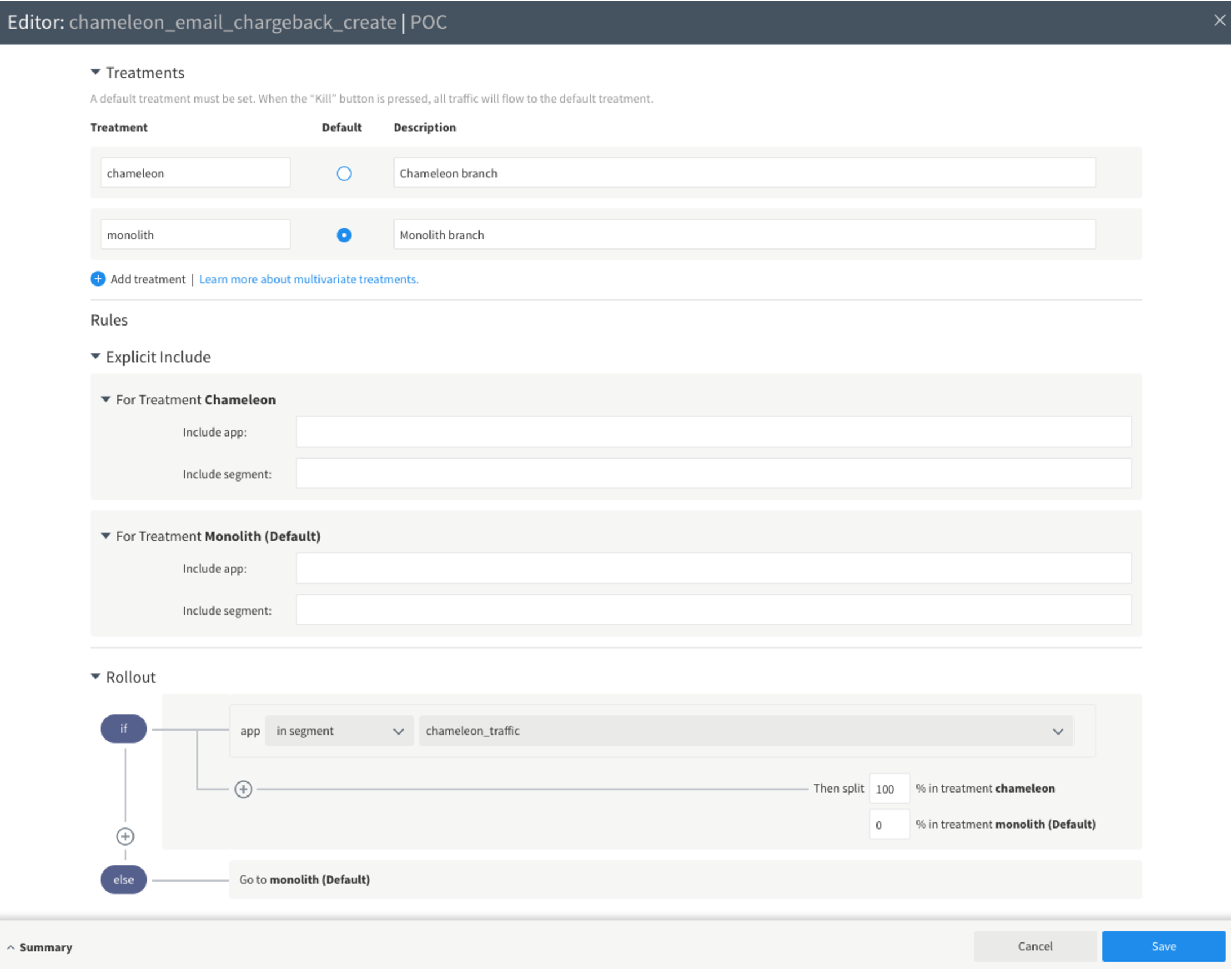
Once the segment is defined, we create a Split in the split editor. This involves creating a default treatment. For example, here the default treatment is to send the traffic to monolith codebase.
We define a rollout plan. In this case 100% of the apps defined in the segment chameleon_traffic will get diverted to the new microservice. If an app id is NOT present the segment, it will continue to get served by the old codebase.
Once all the segments and splits are defined and wired up, you can write the code. In this case, code in PHP stack is as follows
$splitFactory = \SplitIO\Sdk::factory(API_KEY_FOR_SPLITIO, $sdkConfig);
$splitClient = $splitFactory->client();
$treatment = $splitClient->getTreatment($app_id // unique identifier for your app,
'chameleon_email_chargeback_create');
if ($treatment === 'chameleon') {
// insert call to the micro service here
} elseif ($treatment === 'monolith') {
// insert monolith code here
} else {
// insert default code here
}
Using Split, there is an easy way for us to define and test the controlled rollouts across all the internal environments before we enable an experiment and roll it out to the customers.
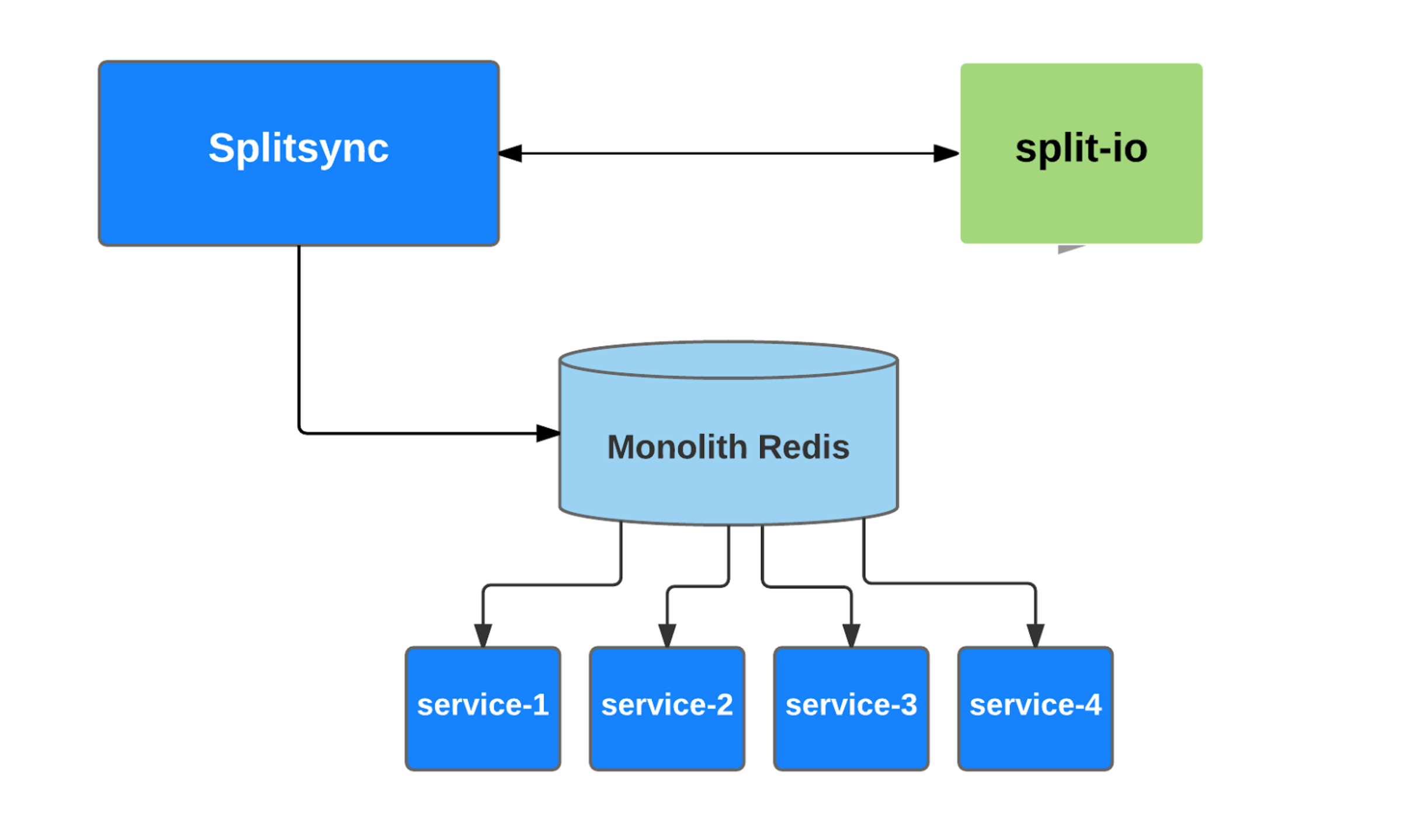
Split provides SDKs for Java, Python, and PHP. Using Split with Java-based microservices was easy since the Java SDK directly talks to the SplitIO service asynchronously, and caches the data locally. This was not the case for other languages. Because of the share-nothing nature of PHP and Python, the SDK architecture is different. For these languages, we use an intermediate service that acts as Synchronizer (SplitSync). This synchronizer is a Kubernetes service. It talks to SplitIO and checks for any changes periodically and updates the cache (Redis) with the changes. Python and PHP SDKs only talk to the cache to get the Split information, this makes the lookup extremely fast, and allows us to share the splits between the Python and PHP codebases.
Conclusion
With Split’s help, we were able to isolate the migrating set of features, then ramp our PHP monolith down and our Java and Python services up in concert. From our user’s perspective, nothing changed, but it’s given us the opportunity to begin work in an entirely new codebase, enabling improvements to the way we do business.
Having more control over our feature rollout process also means we can afford to be more experimental in our feature development process. We have certain customers who love to be the first to have and try new features, even when they’re in beta or under development. Split’s targeting abilities mean we can get new features in front of the customers that want to help us develop and refine them, and make sure no one else is impacted by experimental code.