
Highly Available MySQL Clusters at WePay
This post describes WePay’s highly available MySQL architecture, and how we achieve short outage times during failures.
WePay uses a variety of relational database management systems (RDBMS) and noSQL databases. MySQL remains the main RDBMS that completes all critical operations. The site and all API transactions require MySQL access.
We run multiple MySQL clusters serving different sets of services. Each cluster consists of a master and multiple slaves, where a single MySQL instance (the master) accepts writes. The rest of the nodes (the slaves) replicate the data from master node. We use both semi-synchronous and asynchronous replication for slaves.
The availability of the master node is highly critical. Without a master, an entire cluster cannot accept writes and any incoming changes that require data to be persisted will fail. To support writes, the master node (as well as a cluster of candidate master servers) must be highly available. It is critical to identify the master node in a cluster of available servers and distribute its identity across those servers.
In a failure scenario, like a master node crash, we detect the failure and select a new master from the available cluster of servers. Then, we communicate the identity of the new master to all the servers. The time it takes to detect a failure, select a new master, and advertise its identity to all the servers is the total downtime of a cluster.
Previous Implementation
This section is an overview of our previous implementation and its limitations. In our previous iteration, we used:
- MHA for master failover.
- HAProxy for load balancing. (This was a patched version that modified pools at run time. Standard HAProxy would not allow us to change the of the pool at run time. We had to restart HAProxy for changes to appear. Because of that, we patched HAProxy to update the master and slave pools dynamically.)
- Google routes for failovers between HAProxy.
All clients connected to the same HAProxy. The master and read-only slaves were configured on different ports. In the event of a planned failover:
- We selected a candidate master and triggered a failover.
- MHA was used to perform the following steps:
- Verify if there are any long running updates or inserts happening on master and wait for 10 seconds before killing them.
- MHA updates the global variable read_only to true. This makes the current master non-writable. The server doesn’t permit any client updates.
- Update the HAProxy master pool so master is in maintenance mode. (At this time, none of the MySQL instances are active in the master pool.)
- Perform the role transition to the new master.
- Update the HAProxy master pool again with the new master by making the candidate master active in the master pool.
This worked well during a planned failover. However, the following issues also surfaced:
- Unexpected master crashes have a minimum downtime of 30 minutes to recover and to make the new master completely functional.
- HAproxy became a single point of failure. If there were issues with the HAProxy host, we needed to switch to the backup HAProxy.
- During Google network issues (we run in Google cloud), it became difficult to make changes to the control plane because it’s not guaranteed that changes are reflected properly. We had two HAProxy nodes running in active passive mode. Traffic was only routed to an active HAProxy using Google routes. When Google had network issues, updating routes at run time became a challenging task. There was no 100% guarantee that the changes made while the network issue occurred would be reflected properly.
- Slave lag was calculated from pt-heartbeat. Pt-heartbeat is a 2 part MySQL delay replication monitoring system. The first part is an update instance of pt-heartbeat which connects to the master and updates the timestamp at regular intervals.The second part is a monitor instance of pt-heartbeat which connects to slave and examines the replicated record and computes a difference from current system timestamp. We had first part (update instance) of pt-heartbeat which runs on MHA machine and second part (monitor instance) which was running from an each MySQL instance. Any time skew between the MHA machine and the slates resulted in a miscalculation of slave lag.
In addition to the limitations listed above, managing HAProxy config dynamically was very challenging.
As mentioned, we patched HAProxy and ran our own version. We managed which backend received a request and which one was the backup. Additionally, we used customized hooks to circumvent HAProxy during failover activity.
We started to build our infrastructure in an immutable way with the help of Packer and a config management service (as described in our previous blog post).
With the approach described in this section, adding or changing MySQL servers became arduous because we had to manage HAProxy configs separately.
We have a few partial slaves in our infrastructure. With MHA, we couldn’t add partial slaves to the MHA config because of its limitations. Instead, we had master and primary slaves in the MHA config to make role transition faster, and we handled partial slaves manually after failover was done.
Considerations for a New High Availability Solution
As we scale, we need to adapt to changes in our MySQL clusters. While designing for high availability, we considered the following:
- How much MySQL downtime we can tolerate?
- How reliable is our failover mechanism, and where can it fail?
- Will our solution be able to handle a single Google Zone outage?
- How will our solution scale across zones in a single region?
- How can we detect a split-brain scenario during Google network issues?
- How can we add/delete servers in HAProxy config?
- How can we complete role transition with less or no human intervention?
- Single server time skew should not impact slave lag.
WePays High Availability Solution
Orchestrator, Consul, HAProxy, and pt-heartbeat
Our new high availability solution, coupled with changes to pt-heartbeat, was designed to handle time skews. Our current setup includes:
- Orchestrator to detect failure and complete role transition.
- Two layers of HAProxy.
- The first layer of HAProxy sits on the client machines and connects to the remote (second layer) of HAProxy.
- The second layer of HAProxy is distributed across multiple Google zones that connect to the same set of MySQL servers .
- Hashicorp Consul for the KV store.
- Hashicorp consul-template for managing dynamic configs.
- pt-heartbeat to run on all slaves.
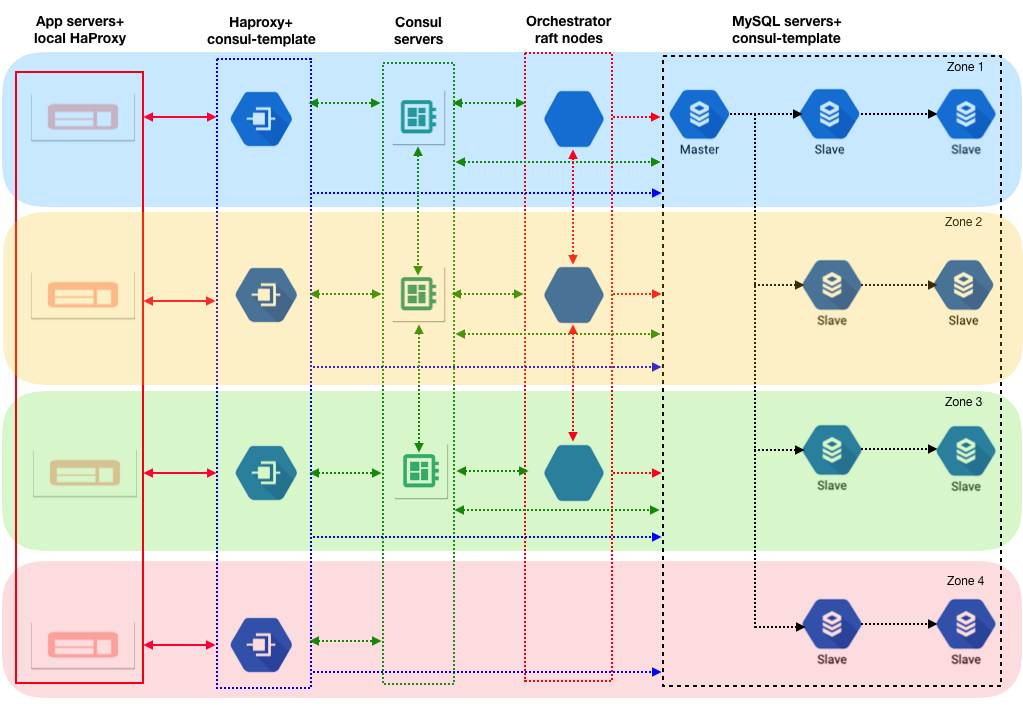
Our new setup addresses most of the limitations we listed in the Previous Implementation section. We introduced many new components, but we simplified and decoupled the failover tasks into smaller chunks.
Application Flow
Let’s see how these individual pieces function in a normal workflow.
On a normal day, the application connects to write and read MySQL hosts via its local HAProxy. The local HAProxy passes the request to the remote (second tier) HAProxy, which is aware of the current master and its slaves.
As noted above in the Previous Implementation section, our limitation was HAProxy. We were forced to failover using Google network routes. In order to avoid that, we use multiple HAProxy instances. There are many ways to achieve high availability in this situation:
- Use Google Cloud LB to utilize all HAProxy as backend.
- Use Github’s GLB with HAProxy.
- Run HAProxy locally along with the application which has the identity of master and slaves.
We chose to use none of the above. We have both a monolith and microservice applications in our environment, and they are spread across a Google region in multiple zones. For the monolith, we run HAProxy locally. For microservices, which reside in Kubernetes, we run an HAProxy sidecar with remote HAProxy configurations. Because of this, applications will not have visibility into who is the current master. Only the remote HAProxy (the second tier) will have details about the master and slaves. As far as applications are concerned, connectivity ends locally.
Local and Remote HAProxy
We run two layers of HAProxy: local and remote. The local HAProxy, which is on client side, always connects to the remote HAProxy, which is located in another zone. This is done on purpose. Consider the following scenario:
- MySQL master and the Orchestrator leader node are in a same zone, and we have one remote HAProxy in that zone.
- During a network issue, if a zone with a MySQL master node present becomes isolated, all instances in that zone also become isolated. This includes clients and one of the remote HAProxy as well.
- Since the Orchestrator master node cannot be reached, a new leader is elected. The new leader detects it can’t reach the MySQL master and triggers a failover.
- The new MySQL master identity is updated on all the remote HAProxy except for the HAProxy which is isolated because of network issues.
- All other zones (which are not impacted by the network issue) start writing to the new master.
- Now, if we have clients in impacted zones connected to same zone as remote HAProxy (which has the network issue), writes can still go to master. This creates a split-brain scenario.
To avoid the scenario above, we connect clients to the remote HAProxy in different zones. If there is a network issue which isolates a single zone, we won’t create a split-brain scenario.
The next section explains how remote HAProxy configs are updated.
Consul KV Store
Consul is a system from HashiCorp that can be used for service discovery, configuration, and segmentation functionality. In our case, we use Consul as a highly available KV store for configuration.
We store the identities of cluster masters and slaves in the consul KV Store. For each cluster, we have the following values stored in the consul KV Store.
- Master fqdn, ipv4, ipv6, and port
- All slaves fqdn, ipv4,ipv6, and port
Each remote HAProxy runs consul-template which listens to changes in consul data.
In our case, consul-template listens to changes in master and slave data using the Consul KV store.
When there are master or slave value changes in the consul KV Store, the remote HAProxy identifies the changes through consul template, which updates the config files, and reloads HAProxy with the updates. All changes are handled automatically without human intervention.
At WePay, we deployed consul across multiple Google zones in a single region. This makes consul highly available because it’s not affected by issues in a single Google zone.
The next section describes how the consul KV store is updated dynamically.
Orchestrator
Orchestrator is MySQL high availability and replication management tool allowing for topology discovery, refactoring and recovery. We run Orchestrator in a raft setup. One server in each Google zone within a single region.
Orchestrator is responsible for:
- Detecting failures
- Performing role transitions
- Communicating the role transition (new master) to consul
Since we run Orchestrator in raft mode, one node is elected as the leader. This leader performs the role transition and communicates changes to other nodes in the raft. In addition, the leader updates the consul KV store with the changes.
Pt-heartbeat
We have a pt-heartbeat script running from all slaves and inserting the row into master. This is a little different than the traditional way where a single server runs a pt-heartbeat script (the MHA machine in our former setup).
Each slave then looks for its own row to calculate lag. With this approach, we eliminate dependence on a single server for slave lag, and time skews don’t result in slave lag.
Since pt-heartbeat is writing to the master, it needs to know the master’s identity. We achieved this by using consul-template. We run consul-template on all MySQL servers, which listens to the same KV store for mastership information. If the master change in the KV store, consul-template updates the pt-heartbeat config and restarts pt-heartbeat.
Planned and unplanned failover
Planned
In a planned failover scenario, the following occurs:
- Orchestrator master node brings all the slaves behind candidate master.
- Orchestrator will run pre-failover checks.
- No DDLs on master.
- No errant transactions in candidate master.
- No long running DML on master.
- Check if consul-client and consul-template are running on remote HAProxy.
- Orchestrator master node triggers the role transition.
- Orchestrator master updates the remaining Orchestrator nodes regarding the master change.
- Orchestrator master updates the consul KV store for the new master.
- Orchestrator will put the old MySQL master behind the current master.
- Remote HAProxy receives the updated the master identity through consul-template.
- Consul-template updates the HAProxy config file and reloads HAProxy.
- Clients connect to the new master.
- Consul-template updates the pt-heartbeat config file on all MySQL nodes and restarts pt-heartbeat.
- Pt-heartbeat starts writing to the new master.
Unplanned
In an unplanned failover scenario, the following occurs:
- Master dies abruptly and orchestrator detects the failure.
- The Orchestrator leader kicks off recovery from the master crash and elects a new master.
- Orchestrator master updates the remaining Orchestrator nodes regarding the new master identity.
- The Orchestrator leader updates the consul KV store for the new master.
- Remote HAProxy received the updated master identity through consul-template.
- Consul-template updates the HAProxy config file and reloads HAProxy.
- Clients connect to the new master.
- Consul-template updates the pt-heartbeat config file on all MySQL nodes and restarts pt-heartbeat.
- Pt-heartbeat starts writing to the new master.
- We remove the failed/crashed master from the slave pool in consul KV store.
Additional Details
Consul and consul-template checks
We only check consul-client and consul-template during failover. In a normal workflow, if consul-client or consul-template is down, HAProxy can still route the traffic to the master and slave. Consul and consul-template are only needed for changes to be reflected.
MySQL GTID and Semi-sync Replication
Our MySQL replication uses GTIDs as well as semi-sync replication.
Even though we use MySQL semi-synchronous replication, it’s not guaranteed that all the data written to master will be synced to slave at the same time. You can read more about this in this blog.
In order to avoid surprises during a master crash, we remove the crashed server out of the pool. We manually verify the server and add it back to pool.
Future Work
- Since we have two layers of HAProxy, we are still working on changing the configs of the local HAProxy dynamically.
- We are looking at changing our proxy layer to proxysql.
- We plan on changing the MySQL server creation using Google snapshots of data disks.
- Scaling up this architecture to multiple regions.
Results
After we rolled out the new architecture, we successfully completed planned and unplanned failovers. We achieved the following:
- Reliable role transition in planned and unplanned failover scenarios.
- Our MySQL server is highly available across a single region.
- We can withstand complete single zone outage.
- We can manage complete network isolation of a single zone.
- Total outage time was kept at around 40-60 seconds (in the worst case scenario). We are working hard to improve this.
Conclusion
Orchestrator, Haproxy, Consul, Consul-template, and pt-heartbeat can be deployed independently, while working as a single cohesive unit. We can scale these servers as needed.
Acknowledgement
We want to thank Pythian for working with us on this project. Special thanks to Daniel Almeida, Gabriel Ciciliani, and Ivan Groenewold.