
Building WePay's data warehouse using BigQuery and Airflow
Over the coming weeks, we’ll be writing a series of posts describing how we’ve built and run WePay’s data warehouse. This series will cover our usage of Google Cloud Platform, BigQuery, and Apache Airflow (incubating), as well as how we handle security, data quality checks, and our plans for the future.
The beginning
We run MySQL as our primary OLTP database at WePay. Most of the data resides in a single monolithic database cluster that runs inside Google compute engine. When we started out, developers, analysts, product managers, and others were all running their analytic queries on a replica of this MySQL cluster. This replica was used to do things like train machine learning models, generate business and financial reports, build business intelligence dashboards, debug production issues, and so on.
This approach had the advantages of being convenient and having up-to-date data (since it was just a replica of the database). The disadvantage of this setup is that MySQL is not very good at handling large analytic-style queries. This is not surprising. It’s meant to be used as a low latency OLTP database, not a data warehouse. As we (and our data) grew, we bumped up against some problems:
- Multi-tenancy issues, where one user would severely degrade the entire cluster.
- Performance problems, timeouts, and queries that never finish.
- Inability to easily run custom logic on the data (UDFs).
It was obvious that we needed to move to a real data warehouse. This post describes that journey, the lessons learned, and the technology that we used.
Picking the stack
WePay made the transition to Google Cloud Platform last year. One of the services that Google provides is BigQuery, a distributed data warehouse built on top of a bunch of great Google technology including Dremel, Borg, Colossus, and Jupiter. We did an evaluation of BigQuery, and decided to use it as our data warehousing solution.
After picking BigQuery, we needed to get data into it. A naive approach would be to run a Python script via CRON that wakes up periodically, selects rows from MySQL, and inserts them into BigQuery. We did this initially as a quick short-term solution. This approach has a number of problems, though:
- What happens if things fail? Should you retry?
- How is monitoring handled? Will anyone know if things failed?
- What if things need to happen in sequence, or depend on each other?
- What if the script runs slowly, and a second iteration of the script starts before the first finishes?
Most of these problems (and many others) are solved by workflow schedulers, so we opted to use one to run our ETL scripts. The four that we looked at were Oozie, Azkaban, Luigi, and Airflow.
Ultimately, we chose to use Airflow. We found it appealing for a number of reasons. The community is great, growing fast, and has a lot of momentum (Airflow just entered Apache Incubator!). Airflow is built with ETL in mind, so it understands things like time data-slices (the last hour’s worth of data). It also allows workflow (DAG) creation via Python scripts, so you can dynamically generate them from code.
With BigQuery and Airflow, let’s cover how we’ve built and run our data warehouse at WePay.
Overview
We run three distinct Google cloud projects for our analytics environments. All three run Airflow independently, and all have BigQuery enabled with their own distinct datasets.
We have multiple projects primarily for security and isolation purposes. Some Google cloud permissions function only at the project level, so having separate projects allows for more granularity over who can see and do things. Multiple projects also gives us more flexibility over quotas, since BigQuery applies quotas at a per-project basis.
The projects address three different use cases:
- ETL: Copy our primary data from our production project into the ETL environment.
- Development analytics: Run ad hoc queries via a UI, or develop Airflow DAGs for data products.
- Production analytics: Run Airflow DAGs for data products that generate output to be consumed by our customers in our production environment.
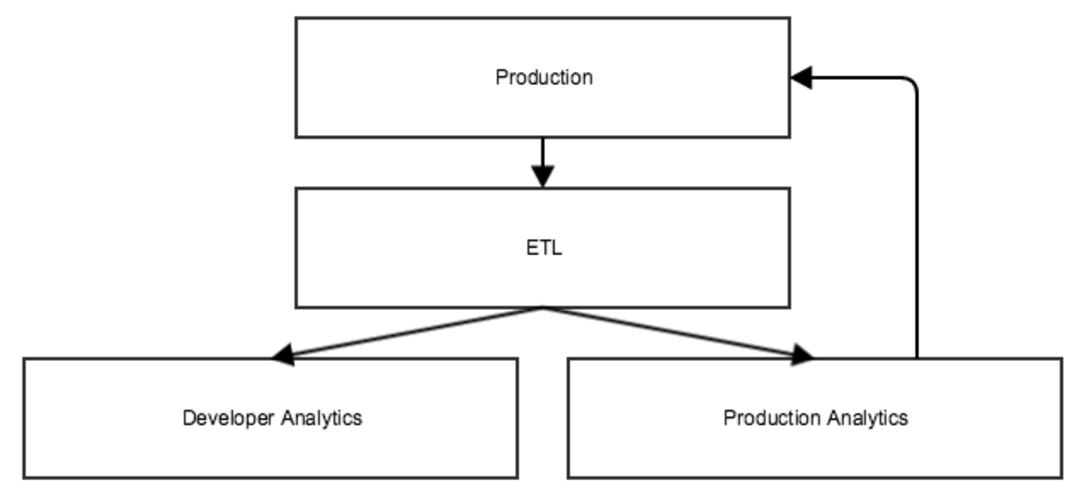
Our production project, where we handle live traffic, contains our primary MySQL database. We export its data periodically into new-line delimited JSON files, which are loaded into Google Cloud Storage buckets in the ETL project. From there, we load the files into BigQuery. This is all done with Airflow.

The datasets in the ETL project are shared out to groups, who can query the datasets using the developer analytics project. Developers can also build Airflow DAGs in developer analytics that query the data to build new derived datasets. If those datasets need to get pushed back into production (for example, if we generate a report that we want to show to our users in a reporting product), then the DAG gets promoted into production analytics when it’s ready to run on an on-going basis. Pushing data from production analytics back into production is done through Google Cloud Storage.
Up next
Stay tuned for our next post, where we’ll go in-depth on how we integrated Airflow with Google cloud, the hooks and operators that we contributed to the project, dynamic DAG generation, and how we operate Airflow.